











आधुनिक सॉफ्टवेयर आर्किटेक्चर में, एप्लीकेशन कोड में उपयोग किए जाने वाले ऑब्जेक्ट-ओरिएंटेड मॉडल और स्थायी स्टोरेज में उपयोग किए जाने वाले संबंधात्मक मॉडल के बीच असंगति एक लगातार चुनौती है। डेवलपर्स को ऐसी स्थितियों का सामना करना पड़ता है जहां क्लास डायग्राम में डेटा संरचना का दृश्य प्रतिनिधित्व डेटाबेस स्कीमा में टेबल और कॉलम की भौतिक व्यवस्था से बहुत अलग होता है। यह अंतर केवल दृश्यात्मक नहीं है; यह एक मूलभूत आर्किटेक्चरल तनाव को दर्शाता है जो डेटा अखंडता की समस्याओं, प्रदर्शन की अवरोधों और बढ़ी हुई रखरखाव लागत के कारण बन सकता है। इन असंगतियों के मूल कारणों को समझना लचीले, स्केलेबल सिस्टम बनाने के लिए आवश्यक है।
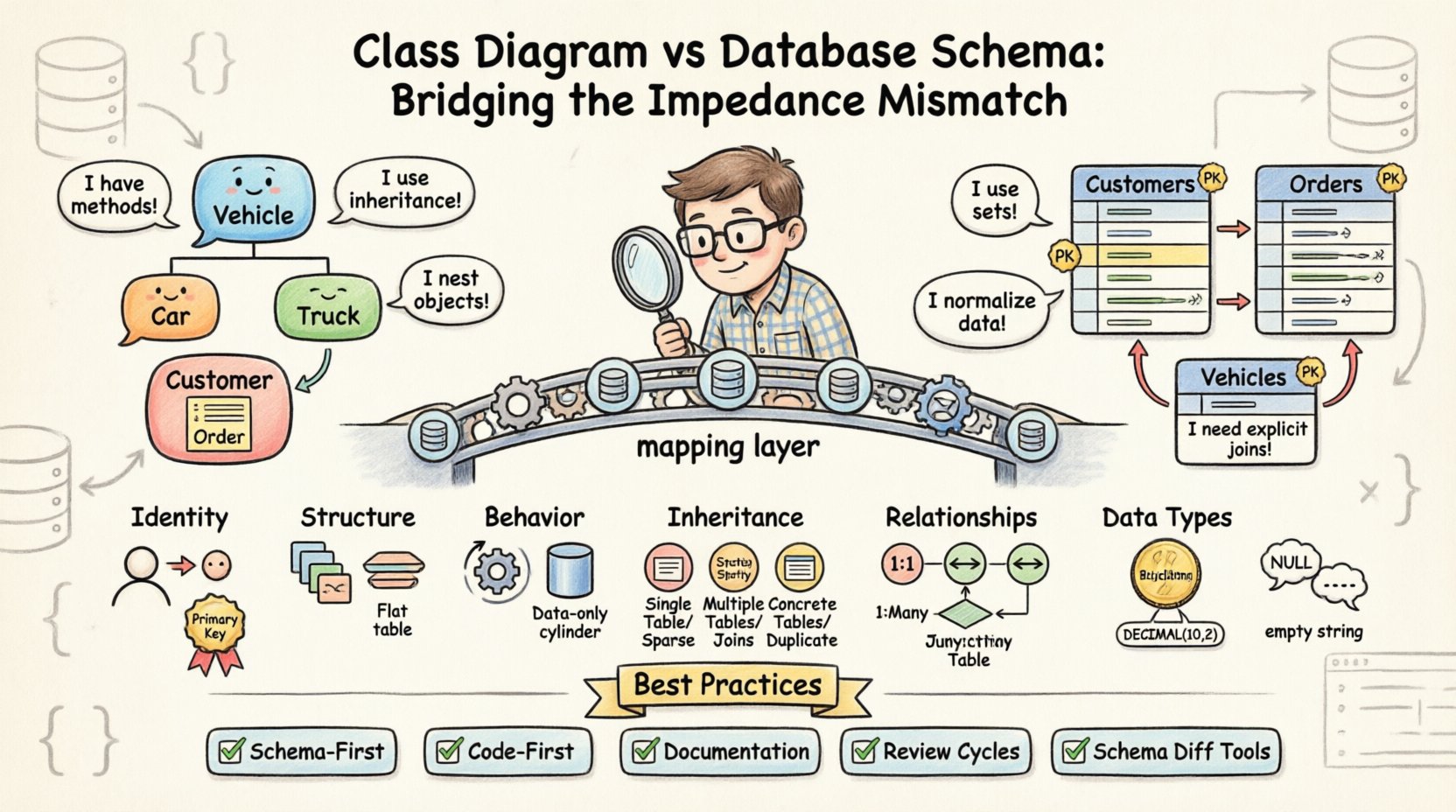
जब क्लास डायग्राम नीचे के डेटाबेस स्कीमा के साथ मेल नहीं खाता है, तो यह इंपेडेंस मिसमैच का निर्माण करता है। इस शब्द का अर्थ है ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग भाषाओं के उपयोग में छिपी चुनौतियों का समूह, जो संबंधात्मक डेटाबेस वातावरण में मौजूद समस्याओं को हल करने के लिए होती है। जबकि ऑब्जेक्ट दुनिया इंस्टेंस, मेथड्स और विरासत पर काम करती है, डेटाबेस दुनिया सेट्स, रोज़ और फॉरेन की पर निर्भर होती है। इस अंतर को पार करने के लिए जानबूझकर डिज़ाइन निर्णय लेने और कठोर वैलिडेशन की आवश्यकता होती है।
🔄 मूल तनाव: ऑब्जेक्ट्स बनाम टेबल
मूल अंतर डेटा स्टोरेज के दर्शन में है। ऑब्जेक्ट-ओरिएंटेड क्लासेस राज्य और व्यवहार को एक साथ संकलित करती हैं। इसके विपरीत, संबंधात्मक डेटाबेस डेटा को अतिरिक्त दोहराव को कम करने के लिए नॉर्मलाइज़ करते हैं। इस विचलन के कारण दोनों मॉडलों के बीच सिंक्रनाइज़ेशन में कठिनाइयाँ उत्पन्न होती हैं।
- पहचान:ऑब्जेक्ट्स को रनटाइम के दौरान मेमोरी रेफरेंस या एक अद्वितीय ऑब्जेक्ट आईडी द्वारा पहचाना जाता है। डेटाबेस प्राइमरी की का उपयोग करते हैं, जो अक्सर ऑटो-इंक्रीमेंटिंग पूर्णांक या UUID होते हैं, जो एप्लीकेशन लाइफसाइकल से स्वतंत्र रूप से मौजूद होते हैं।
- संरचना:एक क्लास में जटिल नेस्टेड ऑब्जेक्ट्स, कलेक्शन और सर्कुलर रेफरेंस हो सकते हैं। एक डेटाबेस टेबल नेस्टेड ऑब्जेक्ट को बिना उसे फ्लैट किए या अलग टेबल बनाए नहीं स्टोर कर सकता है।
- व्यवहार:क्लासेस में डेटा के संचालन करने वाले मेथड्स होते हैं। डेटाबेस टेबल में केवल डेटा होता है; कोई भी लॉजिक स्टोर्ड प्रोसीजर या डेटाबेस लेयर के बाहर हैंडल किया जाना चाहिए।
जब डेवलपर्स ध्यान से एबस्ट्रैक्शन के बिना इन दोनों पैराडाइम्स को सीधे मैप करने की कोशिश करते हैं, तो त्रुटियाँ होती हैं। मैपिंग लेयर अक्सर एक अनुवादक के रूप में काम करती है, लेकिन कोई भी अनुवादक संपूर्ण नहीं होता है। लॉजिक, नल हैंडलिंग और प्रकार के रूपांतरण में बातचीत के नुक्कड़ अक्सर अनुवाद में खो जाते हैं।
🏗️ मैपिंग में संरचनात्मक अंतर
असंगति के सबसे सामान्य स्रोतों में से एक एंटिटीज के बीच संबंधों के प्रबंधन के तरीके को शामिल करता है। क्लास डायग्राम में, संबंधों को अक्सर संबंध को दर्शाने वाली सरल रेखाओं के रूप में दर्शाया जाता है। डेटाबेस स्कीमा में, इन संबंधों के लिए स्पष्ट फॉरेन की प्रतिबंध और अक्सर मध्यवर्ती जॉइन टेबल की आवश्यकता होती है।
विरासत पदानुक्रम
ऑब्जेक्ट-ओरिएंटेड सिस्टम विरासत पर तरोतर बढ़ते हैं। एक वाहन क्लास में उपवर्ग जैसे कार और ट्रक। इससे पॉलीमॉर्फिज्म और कोड रीयूज की अनुमति मिलती है। हालांकि, संबंधात्मक डेटाबेस विरासत का स्वाभाविक समर्थन नहीं करते हैं। इसके मॉडलिंग के लिए इंजीनियर्स को विशिष्ट रणनीतियों में से चयन करना होता है, जिनमें प्रत्येक के अपने लाभ-नुकसान होते हैं।
- पदानुक्रम प्रति टेबल:एक ही टेबल में मूल और सभी उपवर्गों के लिए सभी डेटा स्टोर होता है। यह सरल है लेकिन उपवर्ग-विशिष्ट फील्ड्स के उपयोग पर दुर्लभ कॉलम और नल मानों की ओर जाता है।
- उपवर्ग प्रति टेबल:प्रत्येक क्लास को अपनी टेबल मिलती है। मूल टेबल सामान्य विशेषताओं को रखती है, जबकि बच्चे की टेबल विशिष्ट विशेषताओं को फॉरेन की द्वारा जोड़े गए रूप में रखती है। इससे पूरे ऑब्जेक्ट को प्राप्त करने के लिए जॉइन की जटिलता बढ़ जाती है।
- कॉन्क्रीट क्लास प्रति टेबल:प्रत्येक कॉन्क्रीट क्लास को सभी विशेषताओं वाली पूरी टेबल मिलती है। इससे जॉइन की आवश्यकता नहीं होती है, लेकिन एक ही डेटा को कई टेबल में दोहराने की आवश्यकता होती है।
यदि क्लास डायग्राम में स्पष्ट विरासत वृक्ष दिखाया गया है लेकिन डेटाबेस स्कीमा एकल फ्लैट टेबल का उपयोग करता है, तो स्कीमा तार्किक मॉडल के साथ मेल नहीं खाता है। इससे रखरखाव के दौरान भ्रम पैदा हो सकता है, क्योंकि डेवलपर्स को ऐसे कॉलम की उम्मीद हो सकती है जो फ्लैटनिंग रणनीति के कारण मौजूद नहीं हैं।
संबंध और समावेश
एक विचार करेंग्राहक क्लास जिसमें एक संग्रह हैआदेश वस्तुएँ। क्लास आरेख में, यह एक-से-बहुत संबंध है। डेटाबेस में, इसे आदेशों तालिका में एक विदेशी कुंजी कॉलम द्वारा दर्शाया जाता है जो ग्राहकों तालिका को संदर्भित करता है। हालांकि, संबंध की दिशा अक्सर असंगतियों के कारण होती है।
- बहु-से-बहु संबंध: एक क्लास आरेख में दिखा सकता है
छात्रऔरपाठ्यक्रमबहु-से-बहु संबंध द्वारा जुड़े हुए। डेटाबेस को एक तीसरी तालिका की आवश्यकता होती है, जिसे अक्सर जंक्शन या ब्रिज तालिका कहा जाता है, इसे हल करने के लिए। यदि स्कीमा इस तालिका को छोड़ देती है, तो संबंध को बल नहीं दिया जा सकता है। - कार्डिनैलिटी: एक क्लास आरेख एक वैकल्पिक संबंध (0..*) को इंगित कर सकता है। डेटाबेस स्कीमा को इसे नल-संभव विदेशी कुंजी के साथ प्रतिबिंबित करना चाहिए। यदि स्कीमा NOT NULL प्रतिबंध को लागू करती है, तो यह क्लास परिभाषा के विपरीत होता है।
- कैस्केडिंग हटाना: कोड में, एक माता-पिता वस्तु को हटाने से बच्चों को स्वचालित रूप से हटा दिया जा सकता है। डेटाबेस में, इसके लिए कैस्केडिंग हटाने के नियमों की आवश्यकता होती है। यदि इन्हें कॉन्फ़िगर नहीं किया गया है, तो अनाथ रिकॉर्ड बने रहते हैं, जिससे डेटा अखंडता बिगड़ जाती है।
🛡️ डेटा अखंडता और प्रकार असंगतियाँ
संरचना के बाहर, क्लास में परिभाषित वास्तविक डेटा प्रकार अक्सर डेटाबेस कॉलम प्रकारों के साथ मेल नहीं खाते हैं। जबकि आधुनिक प्रणालियाँ व्यापक मैपिंग क्षमताएँ प्रदान करती हैं, किनारे के मामले अक्सर समस्याएँ उत्पन्न करते हैं।
नल-संभवता प्रतिबंध
ऑब्जेक्ट-ओरिएंटेड भाषाओं में, एक फील्ड अक्सर डिफ़ॉल्ट रूप से नल-संभव होती है, जब तक कि इसे स्पष्ट रूप से प्रारंभ नहीं किया जाता है। संबंधात्मक डेटाबेस में, NOT NULL प्रतिबंध प्रदर्शन और अखंडता अनुकूलन के लिए होता है। यहाँ असंगति रनटाइम त्रुटियों का कारण बनती है।
- डिफ़ॉल्ट मान: एक क्लास एक स्ट्रिंग फील्ड के खाली स्ट्रिंग के रूप में डिफ़ॉल्ट मान के रूप में मान सकती है। डेटाबेस इसे NULL के रूप में डिफ़ॉल्ट कर सकता है। यदि कोड को खाली स्ट्रिंग की उम्मीद है, तो यह NULL प्राप्त करने पर क्रैश हो जाएगा।
- सत्यापन: एप्लीकेशन-स्तरीय सत्यापन एक फील्ड को नल होने की अनुमति दे सकता है। डेटाबेस स्कीमा इसे अस्वीकार करती है। इससे व्यापार तर्क और स्टोरेज लेयर के बीच तनाव उत्पन्न होता है।
संख्यात्मक शुद्धता और स्केल
वित्तीय डेटा को उच्च शुद्धता की आवश्यकता होती है। एक क्लास एक का उपयोग कर सकती हैBigDecimal या दशमलव मुद्रा को संभालने के लिए प्रकार। डेटाबेस को परिभाषित सटीकता और स्केल वाले संगत कॉलम प्रकार का समर्थन करना चाहिए।
- काटना: यदि डेटाबेस कॉलम को परिभाषित किया गया है
दशमलव(10, 2)लेकिन एप्लिकेशन तर्क संग्रहीत करने की कोशिश करता हैदशमलव(10, 4), डेटा का नुकसान चुपचाप या एक त्रुटि के माध्यम से होता है। - फ्लोट बनाम दशमलव: पैसे के लिए फ्लोटिंग-पॉइंट प्रकारों का उपयोग करना एक सामान्य गलत तरीका है। जबकि एक क्लास किसी प्रदर्शन के लिए
डबलका उपयोग कर सकती है, लेकिन डेटाबेस को लेखा-जोखा में त्रुटियों को रोकने के लिए सटीक गणित को लागू करना चाहिए।
🏷️ नामकरण नियम और पहचान
नामकरण में सामंजस्य रखना रखरखाव के लिए महत्वपूर्ण है। हालांकि, प्रोग्रामिंग भाषाओं में उपयोग किए जाने वाले नियम अक्सर डेटाबेस प्रबंधन प्रणालियों में उपयोग किए जाने वाले नियमों से भिन्न होते हैं।
स्नेक_केस बनाम कैमल_केस
जावा और सी# आमतौर पर क्लास प्रॉपर्टीज और फील्ड नामों के लिए कैमल_केस का उपयोग करते हैं। बहुत से संबंधित डेटाबेस टेबल और कॉलम नामों के लिए स्नेक_केस को प्राथमिकता देते हैं। जबकि मैपिंग टूल अक्सर इस रूपांतरण को स्वचालित रूप से संभालते हैं, हाथ से स्कीमा निर्माण इस नियम के उल्लंघन कर सकता है।
- केस संवेदनशीलता: कुछ डेटाबेस केस संवेदनशील होते हैं, जबकि अन्य नहीं होते हैं। एक कॉलम जिसका नाम है
फर्स्टनेमडेटाबेस में कोड में प्रश्न किया जा सकता हैफर्स्टनेमकोड में, जिससे त्रुटियां होती हैं, जो सर्वर कॉन्फ़िगरेशन पर निर्भर करती हैं। - आरक्षित शब्द: क्लास प्रॉपर्टीज उन नामों का उपयोग कर सकती हैं जो डेटाबेस भाषा में आरक्षित कीवर्ड हैं, जैसे कि
आर्डरयाउपयोगकर्ता। इनके लिए उद्धरण या एलियासिंग की आवश्यकता होती है, जो प्रश्न उत्पादन को जटिल बनाती है।
प्राथमिक कुंजियाँ और विदेशी कुंजियाँ
प्राथमिक कुंजी रणनीति का चयन एक और सामान्य बाधा है। क्लासेस अक्सर प्राकृतिक कुंजियों (जैसे उपयोगकर्ता नाम या ईमेल) या सुपरोगेट कुंजियों (जैसे स्वतः उत्पन्न ID) पर निर्भर करते हैं।
- प्राकृतिक कुंजियाँ: व्यवसाय मूल्य को प्राथमिक कुंजी के रूप में उपयोग करने से स्कीमा कठोर हो सकता है। यदि व्यवसाय नियम बदलता है (उदाहरण के लिए, ईमेल पता बदलता है), तो विदेशी कुंजी संदर्भों को हर जगह अपडेट करना होगा।
- सुपरोगेट कुंजियाँ: स्वतः बढ़ते ID का उपयोग जॉइन के लिए सुरक्षित है, लेकिन व्यावसायिक तर्क में कोई सार्थक अर्थ नहीं रखने वाले एक अतिरिक्त कॉलम को जोड़ता है।
⚡ प्रदर्शन व्यापार लाभ
एक क्लास आरेख के अनुरूप स्कीमा डिजाइन करने में प्रदर्शन के प्रभावों को अक्सर नजरअंदाज किया जाता है। सैद्धांतिक सही होना आवश्यक रूप से संचालन दक्षता के बराबर नहीं होता है।
नॉर्मलाइजेशन बनाम डीनॉर्मलाइजेशन
क्लास आरेख अक्सर अतिरेक को रोकने के लिए नॉर्मलाइज्ड डेटा संरचनाओं को दर्शाते हैं। हालांकि, कभी-कभी डेटाबेस प्रदर्शन को बेहतर बनाने के लिए डीनॉर्मलाइजेशन का लाभ मिलता है, जिससे पढ़ने के दौरान आवश्यक जॉइन की संख्या कम हो जाती है।
- जॉइन की जटिलता: एक जटिल क्लास हायरार्की के एक वस्तु को प्राप्त करने के लिए कई जॉइन की आवश्यकता हो सकती है। उच्च ट्रैफिक वाले सिस्टम में, इससे प्रतिक्रिया समय में महत्वपूर्ण गिरावट आ सकती है।
- कैशिंग: डीनॉर्मलाइज्ड डेटा को आसानी से कैश किया जा सकता है। यदि स्कीमा बहुत नॉर्मलाइज्ड है, तो एप्लीकेशन लेयर को जटिल पुनर्निर्माण तर्क करना होगा, जिससे कैशिंग के लाभ को नकार दिया जाता है।
इंडेक्सिंग रणनीतियाँ
इंडेक्स को डेटाबेस स्तर पर परिभाषित किया जाता है ताकि प्रश्नों को तेज किया जा सके, लेकिन वे क्लास आरेख में देखे जाने की बहुत कम संभावना होती है। स्कीमा डिजाइन में इंडेक्स परिभाषाओं की अनुपस्थिति धीमे प्रश्नों के कारण हो सकती है।
- विदेशी कुंजी इंडेक्स: विदेशी कुंजी कॉलम को आदर्श रूप से इंडेक्स किया जाना चाहिए ताकि जॉइन संचालन तेज हो सके। यदि स्कीमा इन इंडेक्स को छोड़ देता है, तो संबंधित डेटा पर खोज के लिए पूरी टेबल का स्कैन किया जाएगा।
- खोज पैटर्न: यदि एप्लीकेशन एक विशिष्ट विशेषता द्वारा अक्सर खोज करता है, तो डेटाबेस इंडेक्स की आवश्यकता होती है। यदि क्लास आरेख इस विशेषता को उजागर करता है लेकिन स्कीमा इसके लिए इंडेक्स नहीं बनाता है, तो प्रदर्शन प्रभावित होगा।
🔍 असंगतियों का पता लगाना और उनका समाधान करना
स्कीमा और मॉडल के बीच विचलन को पहचानना समाधान की पहली कदम है। इस प्रक्रिया में स्वचालित उपकरणों और मैन्युअल ऑडिटिंग का संयोजन आवश्यक होता है।
स्कीमा डिफ टूल्स
स्वचालित तुलना उपकरण अपेक्षित स्थिति (क्लास आरेख या कोड से प्राप्त) और वास्तविक स्थिति (भौतिक डेटाबेस) के बीच अंतरों को उजागर कर सकते हैं।
- परिवर्तन का पता लगाना: ये उपकरण अनुपस्थित कॉलम, परिवर्तित डेटा प्रकार या हटाए गए प्रतिबंधों को पहचान सकते हैं।
- माइग्रेशन स्क्रिप्ट्स: वे मॉडल के अनुरूप स्कीमा को लाने के लिए आवश्यक SQL उत्पन्न कर सकते हैं, जिससे मैन्युअल त्रुटियों को कम किया जा सकता है।
मैन्युअल ऑडिटिंग
स्वचालन उपयोगी है, लेकिन जटिल तर्क के लिए मानवीय समीक्षा आवश्यक है। समीक्षकों को निम्नलिखित की पुष्टि करनी चाहिए:
- क्या सभी क्लास फील्ड डेटाबेस कॉलम द्वारा प्रतिनिधित्व किए जाते हैं?
- क्या डेटा प्रकार लंबाई और शुद्धता सहित बिल्कुल मेल खाते हैं?
- क्या संबंधों को विदेशी कुंजियों के साथ सही तरीके से सीमित किया गया है?
- क्या नामकरण प्रणाली सभी जगह संगत है?
आम मैपिंग परिदृश्य और संभावित समस्याएँ
| मैपिंग परिदृश्य | वर्ग आरेख प्रतिनिधित्व | डेटाबेस स्कीमा प्रतिनिधित्व | संभावित समस्या |
|---|---|---|---|
| एक से एक | दो वर्गों को जोड़ने वाली एक रेखा | एक तालिका में विदेशी कुंजी (एकलता सीमा) | अनुपस्थित एकलता सीमा दोहराव की अनुमति देती है। |
| एक से बहुत | माता वर्ग में सूची संग्रह | बच्चे की तालिका में विदेशी कुंजी | विदेशी कुंजी पर अनुपस्थित सूचीकरण प्रश्नों को धीमा करती है। |
| बहुत से बहुत | लिंक वर्ग या संबंध | दो विदेशी कुंजियों वाली संयोजन तालिका | संयोजन तालिका छोड़ने से डेटा का नुकसान होता है। |
| विरासत | एक्सटेंड्स कीवर्ड या तीर | NULL के साथ एक तालिका या बहुत सारी तालिकाएँ | एकल तालिका में दुर्लभता या बहुत सारी तालिकाओं में जटिल जोड़। |
📝 संरेखण के लिए सर्वोत्तम प्रथाएँ
भविष्य में घर्षण को कम करने के लिए, टीमों को तार्किक और भौतिक मॉडल के बीच संरेखण को प्राथमिकता देने वाली रणनीतियों को अपनाना चाहिए। इसमें तकनीक के अलावा संचार और प्रक्रिया शामिल है।
- स्कीमा-पहले दृष्टिकोण: एप्लिकेशन कोड लिखने से पहले डेटाबेस स्कीमा को परिभाषित करें। इससे यह सुनिश्चित होता है कि स्टोरेज लेयर प्रतिबंधों को निर्धारित करता है, और कोड को उनके अनुसार अनुकूलित करना होगा।
- कोड-पहले दृष्टिकोण: पहले वर्गों को परिभाषित करें, फिर स्कीमा बनाएं। यह विकास के लिए तेज है, लेकिन बाद में अनुकूलन करने में कठिनाई वाली अक्षम भौतिक संरचना बनाने के जोखिम को बढ़ाता है।
- दस्तावेज़ीकरण: एक जीवंत दस्तावेज़ बनाएं जो क्लास के गुणों को डेटाबेस कॉलम से मैप करता है। इसका उपयोग डेवलपर्स और डेटाबेस एडमिनिस्ट्रेटर्स के लिए एकमात्र सच्चाई के स्रोत के रूप में किया जाता है।
- समीक्षा चक्र: कोड समीक्षा प्रक्रिया में डेटाबेस स्कीमा समीक्षा शामिल करें। कोई भी कोड मर्ज नहीं किया जाना चाहिए बिना यह सुनिश्चित किए कि माइग्रेशन स्क्रिप्ट क्लास बदलावों के अनुरूप हैं।
🛠️ पुराने प्रणालियों का प्रबंधन
सभी परियोजनाओं का शुरुआत एक खाली चार्ट से नहीं होती है। बहुत संगठनों को वर्तमान क्लास डायग्राम के अनुरूप नहीं होने वाले पुराने डेटाबेस के साथ काम करना होता है। इस संदर्भ में रिफैक्टरिंग के लिए सावधानी बरतने की आवश्यकता होती है।
- स्ट्रैंगलर फिग पैटर्न: नई सुविधाओं को धीरे-धीरे एक नए स्कीमा में स्थानांतरित करें जबकि पुरानी प्रणाली संचालित रहे। इससे क्लास डायग्राम के विकास की अनुमति मिलती है बिना मौजूदा इंटीग्रेशन को तोड़े।
- व्यूज और स्टेजिंग: नए क्लास डायग्राम के अनुरूप डेटा को प्रस्तुत करने के लिए डेटाबेस व्यूज बनाएं बिना तुरंत आधारभूत टेबलों को बदले।
- आग्रही माइग्रेशन: डेटा को बैच में स्थानांतरित करें। प्रत्येक बैच के बाद अखंडता की जांच करें और अगले बैच में आगे बढ़ें। इससे संक्रमण के दौरान डेटा के दूषित होने का जोखिम कम होता है।
🚀 आगे बढ़ना
क्लास डायग्राम और डेटाबेस स्कीमा के बीच का अंतर सॉफ्टवेयर इंजीनियरिंग में एक अंतर्निहित चुनौती है। यह कंप्यूटरों द्वारा तर्क को प्रक्रिया करने और जानकारी को संग्रहीत करने के तरीकों में मौलिक अंतर के कारण उत्पन्न होता है। इस घर्षण को पूरी तरह से दूर करने वाला कोई आदर्श समाधान नहीं है, लेकिन इसे प्रभावी ढंग से प्रबंधित करने के तरीके हैं।
विरासत, संबंध, डेटा प्रकार और नामकरण पद्धतियों के बारे में गहन समझ के कारण टीमें त्रुटियों की आवृत्ति को कम कर सकती हैं। नियमित ऑडिट और स्वचालित उपकरणों के उपयोग से समय के साथ समन्वय बनाए रखने में मदद मिलती है। लक्ष्य डेटाबेस को कोड की तरह दिखाना नहीं है, बल्कि यह सुनिश्चित करना है कि उनके बीच मैपिंग स्पष्ट, संगत और कार्यक्षम हो। जब भौतिक संग्रहण तार्किक डिज़ाइन के अनुरूप होता है, तो विकास अधिक पूर्वानुमानित हो जाता है और प्रणाली लोड के तहत स्थिर रहती है।