










Trong kiến trúc phần mềm hiện đại, khoảng cách giữa mô hình hướng đối tượng được sử dụng trong mã nguồn ứng dụng và mô hình quan hệ được sử dụng trong lưu trữ bền vững là một thách thức dai dẳng. Các nhà phát triển thường xuyên gặp phải tình huống mà biểu diễn trực quan của các cấu trúc dữ liệu trong sơ đồ lớp khác biệt đáng kể so với bố cục vật lý của các bảng và cột trong lược đồ cơ sở dữ liệu. Sự khác biệt này không chỉ mang tính hình thức; nó đại diện cho sự xung đột kiến trúc cốt lõi có thể dẫn đến các vấn đề về tính toàn vẹn dữ liệu, nghẽn tắc hiệu suất và chi phí bảo trì gia tăng. Hiểu rõ nguyên nhân gốc rễ của những sự không khớp này là điều cần thiết để xây dựng các hệ thống mạnh mẽ, mở rộng được.
Khi sơ đồ lớp không phù hợp với lược đồ cơ sở dữ liệu nền tảng, điều này tạo ra sự không tương thích về trở kháng. Thuật ngữ này mô tả tập hợp các khó khăn vốn có khi sử dụng ngôn ngữ lập trình hướng đối tượng để giải quyết các vấn đề tồn tại trong môi trường cơ sở dữ liệu quan hệ. Trong khi thế giới đối tượng hoạt động dựa trên các thể hiện, phương thức và kế thừa, thì thế giới cơ sở dữ liệu lại phụ thuộc vào tập hợp, hàng và khóa ngoại. Việc lấp đầy khoảng cách này đòi hỏi các quyết định thiết kế có chủ ý và kiểm tra nghiêm ngặt.
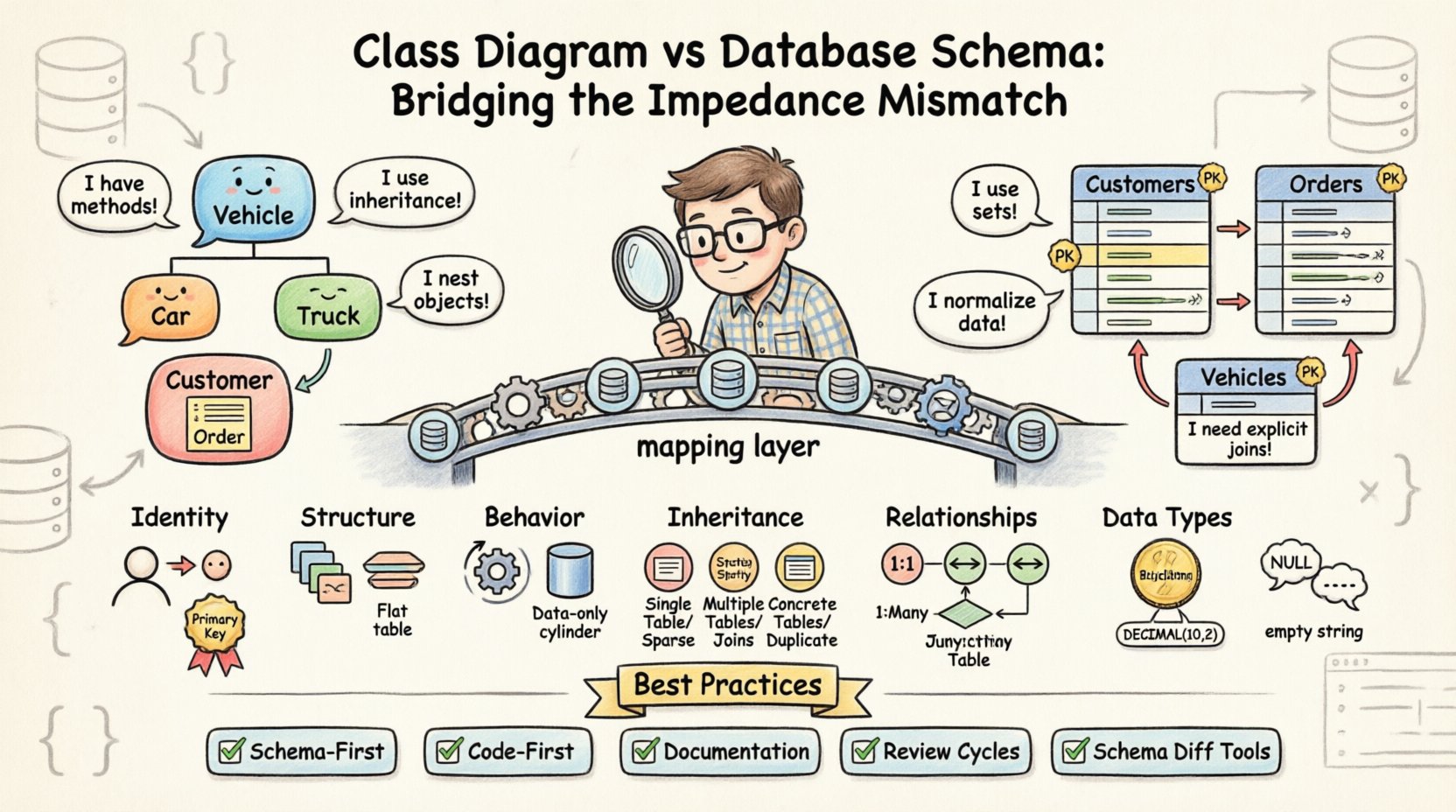
🔄 Mâu thuẫn cốt lõi: Đối tượng so với Bảng
Sự khác biệt cốt lõi nằm ở triết lý lưu trữ dữ liệu. Các lớp hướng đối tượng đóng gói trạng thái và hành vi lại với nhau. Trong khi đó, các cơ sở dữ liệu quan hệ chuẩn hóa dữ liệu để giảm thiểu sự trùng lặp. Sự khác biệt này tạo ra một số khu vực cụ thể mà hai mô hình gặp khó khăn trong việc đồng bộ hóa.
- Định danh:Các đối tượng được xác định bằng tham chiếu bộ nhớ hoặc một định danh đối tượng duy nhất trong quá trình chạy. Cơ sở dữ liệu sử dụng khóa chính, thường là các số nguyên tăng tự động hoặc UUID, tồn tại độc lập với vòng đời ứng dụng.
- Cấu trúc:Một lớp có thể chứa các đối tượng lồng nhau phức tạp, các tập hợp và tham chiếu vòng. Một bảng cơ sở dữ liệu không thể lưu trữ một đối tượng lồng nhau một cách tự nhiên mà không phải làm phẳng nó hoặc tạo ra một bảng riêng biệt.
- Hành vi:Các lớp chứa các phương thức thao tác dữ liệu. Các bảng cơ sở dữ liệu chỉ chứa dữ liệu; mọi logic phải được xử lý thông qua các thủ tục lưu trữ hoặc bên ngoài lớp cơ sở dữ liệu.
Khi các nhà phát triển cố gắng ánh xạ hai mô hình này trực tiếp mà không có sự trừu tượng cẩn thận, lỗi sẽ xảy ra. Lớp ánh xạ thường đóng vai trò như một người dịch, nhưng không có người dịch nào là hoàn hảo. Những chi tiết tinh tế về logic, xử lý giá trị null và chuyển đổi kiểu dữ liệu thường bị mất trong quá trình dịch.
🏗️ Sự khác biệt về cấu trúc trong quá trình ánh xạ
Một trong những nguồn phổ biến nhất của sự không khớp liên quan đến cách xử lý mối quan hệ giữa các thực thể. Trong sơ đồ lớp, các mối quan hệ thường được biểu diễn bằng những đường đơn giản chỉ ra các mối liên kết. Trong lược đồ cơ sở dữ liệu, các mối liên kết này đòi hỏi các ràng buộc khóa ngoại rõ ràng và thường cần các bảng nối trung gian.
Các cấp kế thừa
Các hệ thống hướng đối tượng phát triển mạnh nhờ kế thừa. Một Phương tiện lớp có thể có các lớp con như Ô tô và Xe tải. Điều này cho phép đa hình và tái sử dụng mã nguồn. Tuy nhiên, các cơ sở dữ liệu quan hệ không hỗ trợ kế thừa một cách tự nhiên. Để mô hình hóa điều này, các kỹ sư phải lựa chọn giữa các chiến lược cụ thể, mỗi chiến lược đều có những ưu nhược điểm riêng.
- Bảng theo cấp bậc:Một bảng duy nhất lưu trữ tất cả dữ liệu cho lớp cha và tất cả các lớp con. Điều này đơn giản nhưng dẫn đến các cột thưa thớt và giá trị null khi sử dụng các trường đặc thù cho lớp con.
- Bảng theo lớp con:Mỗi lớp được gán một bảng riêng. Bảng cha lưu trữ các thuộc tính chung, trong khi các bảng con lưu trữ các thuộc tính cụ thể được liên kết bởi khóa ngoại. Điều này làm tăng độ phức tạp của các thao tác nối cần thiết để truy xuất một đối tượng đầy đủ.
- Bảng theo lớp cụ thể:Mỗi lớp cụ thể được gán một bảng đầy đủ chứa tất cả các thuộc tính. Điều này tránh được các thao tác nối nhưng đòi hỏi phải sao chép dữ liệu chung trên nhiều bảng.
Nếu sơ đồ lớp thể hiện rõ ràng một cây kế thừa nhưng lược đồ cơ sở dữ liệu lại sử dụng một bảng phẳng duy nhất, thì lược đồ sẽ không khớp với mô hình logic. Điều này có thể dẫn đến sự nhầm lẫn trong quá trình bảo trì, vì các nhà phát triển có thể mong đợi các cột cụ thể mà không tồn tại do chiến lược làm phẳng dữ liệu.
Liên kết và Tích hợp
Xem xét một Khách hànglớp với một bộ sưu tập của Đơn hàngđối tượng. Trong sơ đồ lớp, đây là mối quan hệ một-nhiều. Trong cơ sở dữ liệu, điều này được biểu diễn bằng một cột khóa ngoại trong bảng Đơn hàngbảng tham chiếu đến bảng Khách hàngbảng. Tuy nhiên, hướng của mối quan hệ thường là nơi xảy ra sự không khớp.
- Mối quan hệ nhiều-nhiều:Sơ đồ lớp có thể hiển thị
Sinh viênvàKhóa họcliên kết với nhau bằng một mối quan hệ nhiều-nhiều. Cơ sở dữ liệu yêu cầu một bảng thứ ba, thường được gọi là bảng nối hoặc bảng cầu, để giải quyết điều này. Nếu lược đồ bỏ qua bảng này, mối quan hệ sẽ không thể được đảm bảo. - Số lượng:Sơ đồ lớp có thể chỉ ra mối quan hệ tùy chọn (0..*). Sơ đồ cơ sở dữ liệu phải phản ánh điều này bằng các khóa ngoại có thể null. Nếu sơ đồ buộc ràng buộc NOT NULL, điều đó mâu thuẫn với định nghĩa lớp.
- Xóa lan truyền:Trong mã nguồn, việc xóa một đối tượng cha có thể tự động xóa các đối tượng con. Trong cơ sở dữ liệu, điều này yêu cầu các quy tắc xóa lan truyền. Nếu không cấu hình, các bản ghi bị bỏ rơi vẫn tồn tại, làm hỏng tính toàn vẹn dữ liệu.
🛡️ Tính toàn vẹn dữ liệu và sự không khớp kiểu dữ liệu
Vượt ra ngoài cấu trúc, các kiểu dữ liệu thực tế được định nghĩa trong lớp thường không khớp với kiểu cột trong cơ sở dữ liệu. Mặc dù các hệ thống hiện đại cung cấp khả năng ánh xạ rộng rãi, nhưng các trường hợp đặc biệt thường gây ra vấn đề.
Ràng buộc khả năng null
Trong các ngôn ngữ hướng đối tượng, một trường thường có thể null mặc định trừ khi được khởi tạo rõ ràng. Trong cơ sở dữ liệu quan hệ, ràng buộc NOT NULL là một tối ưu hóa về hiệu suất và tính toàn vẹn. Sự không khớp ở đây dẫn đến ngoại lệ tại thời điểm chạy.
- Giá trị mặc định:Một lớp có thể giả định rằng một trường chuỗi mặc định là chuỗi rỗng. Cơ sở dữ liệu có thể mặc định nó là NULL. Mã nguồn mong đợi chuỗi rỗng sẽ bị sập nếu nhận được NULL.
- Xác thực:Xác thực ở cấp độ ứng dụng có thể cho phép một trường là null. Sơ đồ cơ sở dữ liệu từ chối điều đó. Điều này tạo ra mâu thuẫn giữa logic kinh doanh và lớp lưu trữ.
Độ chính xác và độ phân giải số
Dữ liệu tài chính yêu cầu độ chính xác cao. Một lớp có thể sử dụng một BigDecimal hoặc Thập phân kiểu để xử lý tiền tệ. Cơ sở dữ liệu phải hỗ trợ kiểu cột tương ứng với độ chính xác và độ phân giải được xác định.
- Cắt bỏ: Nếu cột cơ sở dữ liệu được định nghĩa là
DECIMAL(10, 2)nhưng logic ứng dụng cố gắng lưu trữDECIMAL(10, 4), mất dữ liệu xảy ra một cách im lặng hoặc thông qua lỗi. - Float so với Thập phân: Sử dụng kiểu số dấu phẩy động cho tiền tệ là một mẫu sai lầm phổ biến. Mặc dù một lớp có thể sử dụng
doubleđể cải thiện hiệu suất, cơ sở dữ liệu nên buộc thực hiện phép toán chính xác để ngăn lỗi làm tròn trong kế toán.
🏷️ Quy ước đặt tên và Định danh
Tính nhất quán trong đặt tên rất quan trọng đối với khả năng bảo trì. Tuy nhiên, các quy ước được sử dụng trong ngôn ngữ lập trình thường khác biệt với những quy ước được sử dụng trong hệ quản trị cơ sở dữ liệu.
Snake_case so với CamelCase
Java và C# thường sử dụng camelCase cho thuộc tính lớp và tên trường. Nhiều cơ sở dữ liệu quan hệ ưu tiên snake_case cho tên bảng và cột. Mặc dù các công cụ ánh xạ thường xử lý chuyển đổi này một cách tự động, nhưng việc tạo lược đồ thủ công có thể vi phạm quy tắc này.
- Phân biệt chữ hoa chữ thường: Một số cơ sở dữ liệu phân biệt chữ hoa chữ thường, trong khi một số khác thì không. Một cột được đặt tên là
FirstNametrong cơ sở dữ liệu có thể được truy vấn dưới dạngfirstnametrong mã nguồn, dẫn đến lỗi tùy thuộc vào cấu hình máy chủ. - Từ khóa được bảo lưu: Các thuộc tính lớp có thể sử dụng tên là từ khóa được bảo lưu trong ngôn ngữ cơ sở dữ liệu, chẳng hạn như
OrderhoặcUser. Những từ này yêu cầu đặt trong dấu ngoặc kép hoặc dùng biệt danh, điều này làm phức tạp quá trình tạo truy vấn.
Khóa chính và Khóa ngoại
Việc lựa chọn chiến lược khóa chính là một điểm gây khó khăn phổ biến khác. Các lớp thường phụ thuộc vào các khóa tự nhiên (như tên người dùng hoặc địa chỉ email) hoặc các khóa thay thế (như ID được tạo tự động).
- Khóa tự nhiên:Sử dụng một giá trị kinh doanh làm khóa chính có thể khiến lược đồ trở nên cứng nhắc. Nếu quy tắc kinh doanh thay đổi (ví dụ: địa chỉ email thay đổi), các tham chiếu khóa ngoại phải được cập nhật ở mọi nơi.
- Khóa thay thế:Sử dụng ID tăng tự động an toàn hơn cho các thao tác nối nhưng lại tạo thêm một cột không mang ý nghĩa ngữ nghĩa trong logic kinh doanh.
⚡ Các thỏa hiệp về hiệu suất
Thiết kế một lược đồ phù hợp với sơ đồ lớp thường bỏ qua các hệ quả về hiệu suất. Tính chính xác lý thuyết không phải lúc nào cũng tương đương với hiệu quả vận hành.
Chuẩn hóa so với phi chuẩn hóa
Sơ đồ lớp thường phản ánh các cấu trúc dữ liệu đã được chuẩn hóa để tránh trùng lặp. Tuy nhiên, hiệu suất cơ sở dữ liệu đôi khi được cải thiện nhờ vào việc phi chuẩn hóa để giảm số lượng thao tác nối trong các thao tác đọc.
- Độ phức tạp của thao tác nối:Một cấu trúc phân cấp lớp phức tạp có thể yêu cầu nhiều thao tác nối để lấy một đối tượng duy nhất. Trong các hệ thống có lưu lượng cao, điều này có thể làm giảm đáng kể thời gian phản hồi.
- Bộ nhớ đệm:Dữ liệu đã được phi chuẩn hóa có thể được lưu trữ trong bộ nhớ đệm dễ dàng hơn. Nếu lược đồ quá chuẩn hóa, lớp ứng dụng phải thực hiện logic phục hồi phức tạp, làm mất đi lợi ích của việc sử dụng bộ nhớ đệm.
Chiến lược chỉ mục
Các chỉ mục được định nghĩa ở cấp độ cơ sở dữ liệu để tăng tốc truy vấn, nhưng chúng hiếm khi xuất hiện trong sơ đồ lớp. Sự vắng mặt của định nghĩa chỉ mục trong thiết kế lược đồ có thể dẫn đến các truy vấn chậm.
- Chỉ mục khóa ngoại:Các cột khóa ngoại nên được chỉ mục lý tưởng để tăng tốc thao tác nối. Nếu lược đồ bỏ qua các chỉ mục này, các thao tác tìm kiếm dữ liệu liên quan sẽ phải quét toàn bộ bảng.
- Mẫu tìm kiếm: Nếu ứng dụng thường xuyên tìm kiếm theo một thuộc tính cụ thể, thì chỉ mục cơ sở dữ liệu là cần thiết. Nếu sơ đồ lớp nhấn mạnh thuộc tính này nhưng lược đồ không chỉ mục hóa nó, hiệu suất sẽ bị ảnh hưởng.
🔍 Phát hiện và giải quyết các sự khác biệt
Xác định nơi lược đồ khác biệt với mô hình là bước đầu tiên hướng tới giải pháp. Quá trình này đòi hỏi sự kết hợp giữa các công cụ tự động hóa và kiểm tra thủ công.
Công cụ so sánh lược đồ
Các công cụ so sánh tự động có thể làm nổi bật sự khác biệt giữa trạng thái mong đợi (được suy ra từ sơ đồ lớp hoặc mã nguồn) và trạng thái thực tế (cơ sở dữ liệu vật lý).
- Phát hiện thay đổi: Các công cụ này có thể xác định các cột bị thiếu, kiểu dữ liệu đã thay đổi hoặc ràng buộc đã bị xóa.
- Các tập lệnh di chuyển: Chúng có thể tạo ra SQL cần thiết để đưa lược đồ phù hợp với mô hình, giảm thiểu lỗi do thao tác thủ công.
Kiểm tra thủ công
Tự động hóa là hữu ích, nhưng kiểm tra thủ công là cần thiết cho các logic phức tạp. Người kiểm tra cần xác minh các điều sau:
- Tất cả các trường lớp có được biểu diễn bởi các cột cơ sở dữ liệu không?
- Các kiểu dữ liệu có khớp chính xác không, bao gồm cả độ dài và độ chính xác?
- Các mối quan hệ có được ràng buộc đúng cách bằng khóa ngoại không?
- Các quy ước đặt tên có nhất quán trên toàn bộ hệ thống không?
Các tình huống ánh xạ phổ biến và các vấn đề tiềm ẩn
| Tình huống ánh xạ | Biểu diễn sơ đồ lớp | Biểu diễn lược đồ cơ sở dữ liệu | Vấn đề tiềm ẩn |
|---|---|---|---|
| Một-đối-một | Một đường nối kết nối hai lớp | Khóa ngoại trong một bảng (ràng buộc duy nhất) | Thiếu ràng buộc duy nhất cho phép các bản ghi trùng lặp. |
| Một-đối-nhiều | Bộ sưu tập danh sách trong lớp cha | Khóa ngoại trong bảng con | Thiếu chỉ mục trên khóa ngoại làm chậm các truy vấn. |
| Nhiều-đối-nhiều | Lớp liên kết hoặc mối quan hệ | Bảng liên kết với hai khóa ngoại | Bỏ qua bảng liên kết dẫn đến mất dữ liệu. |
| Kế thừa | Từ khóa extends hoặc mũi tên | Bảng duy nhất với NULLs hoặc nhiều bảng | Tính thưa thớt trong bảng duy nhất hoặc các phép nối phức tạp trong nhiều bảng. |
📝 Các thực hành tốt nhất để đảm bảo sự đồng bộ
Để giảm thiểu sự bất tiện trong tương lai, các đội nhóm nên áp dụng các chiến lược ưu tiên sự đồng bộ giữa mô hình logic và mô hình vật lý. Điều này liên quan đến giao tiếp và quy trình, chứ không chỉ là công nghệ.
- Phương pháp tiếp cận theo lược đồ: Xác định lược đồ cơ sở dữ liệu trước khi viết mã ứng dụng. Điều này đảm bảo lớp lưu trữ sẽ xác định các ràng buộc, và mã nguồn phải thích nghi với chúng.
- Phương pháp tiếp cận theo mã nguồn: Xác định các lớp trước, sau đó sinh lược đồ. Phương pháp này nhanh hơn trong phát triển nhưng tiềm ẩn rủi ro tạo ra cấu trúc vật lý kém hiệu quả, khó tối ưu hóa về sau.
- Tài liệu:Duy trì một tài liệu sống động, ánh xạ các thuộc tính lớp sang các cột cơ sở dữ liệu. Điều này phục vụ như một nguồn thông tin duy nhất cho các nhà phát triển và quản trị viên cơ sở dữ liệu.
- Vòng kiểm tra:Bao gồm việc kiểm tra sơ đồ cơ sở dữ liệu trong quy trình kiểm tra mã nguồn. Không có mã nào được gộp lại mà không xác minh các tập lệnh di chuyển khớp với các thay đổi lớp.
🛠️ Xử lý các hệ thống cũ
Không phải dự án nào cũng bắt đầu từ một bản trắng. Nhiều tổ chức phải đối mặt với các cơ sở dữ liệu cũ không khớp với sơ đồ lớp hiện tại. Việc tái cấu trúc trong bối cảnh này đòi hỏi sự cẩn trọng.
- Mô hình Cây Strangler Fig:Từ từ chuyển chức năng mới sang sơ đồ mới trong khi hệ thống cũ vẫn hoạt động. Điều này cho phép sơ đồ lớp phát triển mà không làm gián đoạn các tích hợp hiện có.
- Các view và giai đoạn thử nghiệm:Tạo các view cơ sở dữ liệu để trình bày dữ liệu theo định dạng phù hợp với sơ đồ lớp mới mà không thay đổi ngay các bảng nền tảng.
- Di chuyển từng bước:Di chuyển dữ liệu theo từng đợt. Xác minh tính toàn vẹn sau mỗi đợt trước khi chuyển sang đợt tiếp theo. Điều này làm giảm thiểu rủi ro lỗi dữ liệu trong quá trình chuyển đổi.
🚀 Tiến bước về phía trước
Khoảng cách giữa sơ đồ lớp và sơ đồ cơ sở dữ liệu là một thách thức vốn có trong kỹ thuật phần mềm. Nó xuất phát từ sự khác biệt cốt lõi giữa cách máy tính xử lý logic và cách chúng lưu trữ thông tin. Không có giải pháp hoàn hảo nào có thể loại bỏ hoàn toàn sự mâu thuẫn này, nhưng có những chiến lược để quản lý nó một cách hiệu quả.
Bằng cách hiểu rõ các chi tiết về kế thừa, mối quan hệ, kiểu dữ liệu và quy ước đặt tên, các đội ngũ có thể giảm tần suất lỗi. Việc kiểm tra định kỳ và sử dụng các công cụ tự động giúp duy trì sự đồng bộ theo thời gian. Mục tiêu không phải là làm cho cơ sở dữ liệu trông giống hệt mã nguồn, mà là đảm bảo rằng bản đồ giữa chúng minh bạch, nhất quán và hiệu suất cao. Khi lưu trữ vật lý phù hợp với thiết kế logic, quá trình phát triển trở nên dự đoán được hơn, và hệ thống duy trì ổn định dưới tải.