











現代のソフトウェアアーキテクチャにおいて、アプリケーションコードで使用されるオブジェクト指向モデルと、永続的ストレージで使用されるリレーショナルモデルとの間の乖離は、常に続く課題である。開発者は、クラス図におけるデータ構造の視覚的表現が、データベーススキーマにおけるテーブルやカラムの物理的配置と大きく異なる状況を頻繁に経験する。この違いは単なる見た目の問題ではない。データ整合性の問題、パフォーマンスのボトルネック、保守コストの増加を引き起こす根本的なアーキテクチャ上の摩擦を示している。こうした不一致の根本原因を理解することは、堅牢でスケーラブルなシステムを構築する上で不可欠である。
クラス図が下位のデータベーススキーマと一致しない場合、インピーダンスミスマッチが生じる。この用語は、リレーショナルデータベース環境に存在する問題をオブジェクト指向プログラミング言語で解決しようとする際に内在する困難を指す。オブジェクト世界はインスタンス、メソッド、継承に基づいて動作するが、データベース世界は集合、行、外部キーに依存している。このギャップを埋めるには、意図的な設計意思決定と厳密な検証が必要となる。
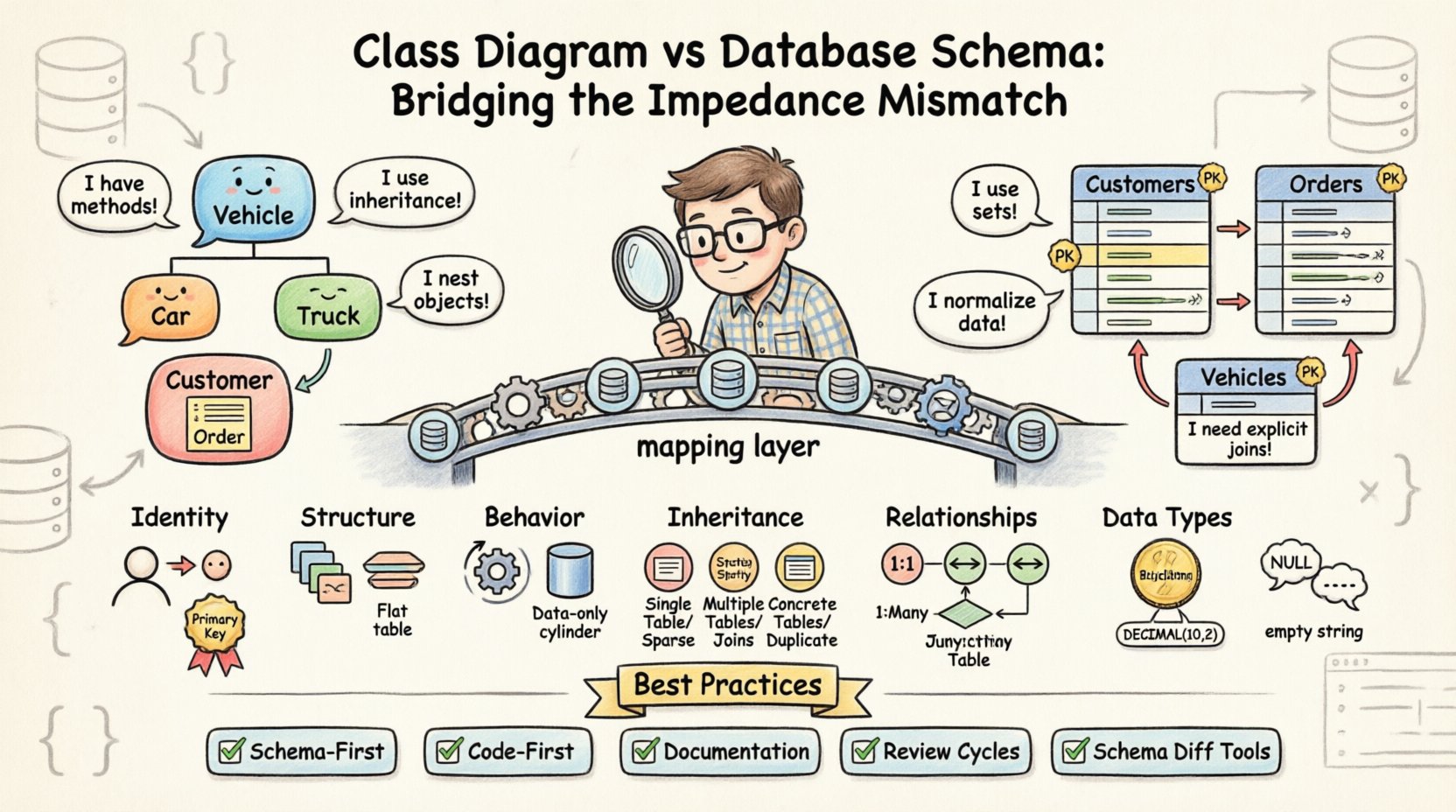
🔄 核心的な緊張:オブジェクト vs. テーブル
根本的な違いは、データ保存の哲学にある。オブジェクト指向のクラスは状態と振る舞いを一緒にカプセル化する。一方、リレーショナルデータベースはデータの重複を減らすために正規化を行う。この違いにより、両モデルが同期しにくい特定の領域が生じる。
- 識別子:オブジェクトは実行時、メモリ参照または一意のオブジェクト識別子によって識別される。データベースは主キー(通常は自動増分の整数またはUUID)を使用し、これらはアプリケーションのライフサイクルとは独立して存在する。
- 構造:クラスは複雑なネストされたオブジェクト、コレクション、循環参照を持つことができる。データベースのテーブルは、ネストされたオブジェクトをフラット化するか別テーブルを作成しない限り、ネイティブにネストされたオブジェクトを格納できない。
- 振る舞い:クラスにはデータを操作するメソッドが含まれる。データベースのテーブルにはデータのみが含まれる。論理処理はストアドプロシージャまたはデータベース層の外で処理される必要がある。
開発者が慎重な抽象化を欠いて、これらの二つのパラダイムを直接マッピングしようとすると、エラーが発生する。マッピング層はしばしば翻訳者として機能するが、完璧な翻訳者は存在しない。論理のニュアンス、nullの扱い、型変換の細部は、翻訳の過程で頻繁に失われる。
🏗️ マッピングにおける構造的不一致
不一致の最も一般的な原因の一つは、エンティティ間の関係の扱い方にある。クラス図では、関係はしばしば単純な線で示され、関連を表している。一方、データベーススキーマでは、これらの関連には明示的な外部キー制約が必要であり、しばしば中間の結合テーブルも必要となる。
継承階層
オブジェクト指向システムは継承によって成り立つ。Vehicle クラスには、Car および Truck といったサブクラスを持つことがある。これによりポリモーフィズムとコード再利用が可能になる。しかし、リレーショナルデータベースは継承をネイティブにサポートしていない。これをモデル化するには、エンジニアが特定の戦略のうちから選択しなければならず、それぞれにトレードオフがある。
- 階層ごとのテーブル: 単一のテーブルが親クラスおよびすべてのサブクラスのデータを格納する。これはシンプルだが、サブクラス固有のフィールドを使用する際に、スパースなカラムやnull値が発生する。
- サブクラスごとのテーブル: 各クラスに独自のテーブルが割り当てられる。親テーブルには共通の属性が格納され、子テーブルには外部キーでリンクされた固有の属性が格納される。これにより、完全なオブジェクトを取得するために必要な結合の複雑さが増す。
- 具体的クラスごとのテーブル: すべての具体的なクラスに、すべての属性を含む完全なテーブルが割り当てられる。結合を回避できるが、共通データを複数のテーブルに重複して格納する必要がある。
クラス図に明確な継承ツリーが示されているが、データベーススキーマが単一のフラットテーブルを使用している場合、スキーマは論理モデルと一致しない。これは保守中に混乱を招く可能性があり、開発者がフラット化戦略のため存在しない特定のカラムを期待してしまうからである。
関連と集約
次を検討してください:顧客クラスは、注文オブジェクトのコレクションを持つ。クラス図では、これは1対多の関係である。データベースでは、注文テーブルに、顧客テーブルを参照する外部キー列として表現される。しかし、関係の方向性は、しばしば不一致が生じる場所である。
- 多対多の関係:クラス図では、
生徒と授業多対多の関連でリンクされている可能性がある。データベースでは、この関係を解決するために、通常「結合テーブル」または「ブリッジテーブル」と呼ばれる第三者のテーブルが必要となる。スキーマでこのテーブルが省略されている場合、関係は強制されない。 - 基数:クラス図では、オプションの関係(0..*)を示す可能性がある。データベーススキーマは、この関係をNullableな外部キーで反映しなければならない。スキーマがNOT NULL制約を強制する場合、クラス定義と矛盾する。
- 連鎖削除:コードでは、親オブジェクトを削除すると子オブジェクトが自動的に削除される可能性がある。データベースでは、これには連鎖削除ルールが必要となる。これらの設定が行われていない場合、孤立したレコードが残り、データ整合性が損なわれる。
🛡️ データ整合性と型の不一致
構造を超えて、クラスで定義された実際のデータ型は、しばしばデータベースのカラム型と一致しない。現代のシステムは広範なマッピング機能を提供しているが、エッジケースが頻繁に問題を引き起こす。
Null許容制約
オブジェクト指向言語では、明示的に初期化されない限り、フィールドはデフォルトでNullを許容する。リレーショナルデータベースでは、NOT NULL制約はパフォーマンスと整合性の最適化である。ここでの不一致は、実行時例外を引き起こす。
- デフォルト値:クラスは、文字列フィールドがデフォルトで空文字列であると仮定する可能性がある。データベースでは、それがNULLにデフォルトされる可能性がある。空文字列を期待するコードがNULLを受け取るとクラッシュする。
- 検証:アプリケーションレベルの検証では、フィールドがNullを許容する可能性がある。データベーススキーマはそれを拒否する。これにより、ビジネスロジックとストレージレイヤーの間に矛盾が生じる。
数値の精度とスケール
金融データには高い精度が必要である。クラスでは、BigDecimal または 小数通貨を扱うための型。データベースは、明確に定義された精度とスケールを持つ対応する列型をサポートしなければならない。
- 切り捨て: データベースの列が以下のように定義されている場合、
DECIMAL(10, 2)しかしアプリケーションのロジックが以下を保存しようとする場合、DECIMAL(10, 4)、データ損失が静かに発生するか、エラーを通じて発生する。 - 浮動小数点型 vs. 小数型: お金に浮動小数点型を使用することは一般的な反パターンである。クラスがパフォーマンス向上のために
doubleを使用するかもしれないが、データベースは会計における丸め誤差を防ぐために正確な算術を強制すべきである。
🏷️ 名前付け規則と識別子
名前の一貫性は保守性にとって不可欠である。しかし、プログラミング言語で使われる規則は、データベース管理システムで使われる規則としばしば異なる。
スネークケース vs. キャメルケース
JavaやC#は、通常クラスのプロパティやフィールド名にキャメルケースを使用する。多くのリレーショナルデータベースは、テーブル名や列名にスネークケースを好む。マッピングツールはこの変換を自動的に行うことが多いが、手動でのスキーマ作成ではこのルールに違反する可能性がある。
- 大文字小文字の区別: 一部のデータベースは大文字小文字を区別するが、他のデータベースは区別しない。列名が
FirstNameのデータベース列がコード内でfirstnameとしてクエリされる可能性があり、サーバーの設定によってエラーが発生する。 - 予約語: クラスのプロパティが、データベース言語の予約語であるような名前を使用する可能性がある。たとえば
OrderまたはUserなどである。これらは引用符を使用するか別名を付ける必要があり、クエリ生成を複雑にする。
主キーと外部キー
プライマリキー戦略の選択は、別の一般的な摩擦要因です。クラスはしばしば自然キー(ユーザー名やメールアドレスなど)またはサロゲートキー(自動生成されたIDなど)に依存します。
- 自然キー:ビジネス値をプライマリキーとして使用すると、スキーマが硬直化します。ビジネスルールが変更された場合(例:メールアドレスが変更された場合)、外部キー参照はすべてで更新されなければなりません。
- サロゲートキー:自動増分IDを使用すると、結合操作においてより安全ですが、ビジネスロジックにおいて意味を持たない追加のカラムが導入されます。
⚡ パフォーマンスのトレードオフ
クラス図に一致するスキーマを設計する際、パフォーマンスへの影響を無視しがちです。理論的な正しさが常に運用効率を意味するわけではありません。
正規化 vs. 非正規化
クラス図はしばしば冗長性を避けるために正規化されたデータ構造を反映します。しかし、データベースのパフォーマンスは、読み取り操作中に必要な結合の数を減らすために、非正規化が有効な場合もあります。
- 結合の複雑さ:複雑なクラス階層は、単一のオブジェクトを取得するために複数の結合を必要とする場合があります。高トラフィックシステムでは、これにより応答時間が著しく低下する可能性があります。
- キャッシュ:非正規化されたデータは、より簡単にキャッシュできます。スキーマが正規化しすぎている場合、アプリケーション層で複雑な再構成ロジックを実行しなければならず、キャッシュの利点が相殺されます。
インデックス戦略
インデックスはデータベースレベルで定義され、クエリの高速化を目的としていますが、クラス図にはほとんど表示されません。スキーマ設計にインデックス定義が欠けていると、クエリが遅くなる原因になります。
- 外部キーインデックス:外部キーのカラムは、結合操作を高速化するために理想的にはインデックスを設定すべきです。スキーマでこれらのインデックスが省略されていると、関連データの検索はテーブル全体をスキャンすることになります。
- 検索パターン:アプリケーションが特定の属性で頻繁に検索する場合、データベースインデックスが必要です。クラス図でその属性が強調されているのに、スキーマでインデックスが設定されていないと、パフォーマンスが低下します。
🔍 マッチングの不一致の検出と解決
スキーマがモデルからどの点で逸脱しているかを特定することは、解決への第一歩です。このプロセスには、自動化ツールと手動による監査の組み合わせが必要です。
スキーマ差分ツール
自動比較ユーティリティは、期待される状態(クラス図またはコードから導出)と実際の状態(物理データベース)の違いを強調できます。
- 変更検出:これらのツールは、欠落しているカラム、変更されたデータ型、または削除された制約を特定できます。
- マイグレーションスクリプト:これらは、スキーマをモデルに合わせるためのSQLを生成でき、手動によるエラーを減らすことができます。
手動監査
自動化は役立ちますが、複雑なロジックには人間のレビューが必要です。レビュアーは以下の点を確認する必要があります:
- すべてのクラスフィールドがデータベースカラムで表現されていますか?
- データ型は長さや精度を含めて正確に一致していますか?
- 関係は外部キーによって適切に制約されていますか?
- 命名規則は全体的に一貫していますか?
一般的なマッピングのシナリオと潜在的な問題
| マッピングのシナリオ | クラス図の表現 | データベーススキーマの表現 | 潜在的な問題 |
|---|---|---|---|
| 1対1 | 2つのクラスを結ぶ単一の線 | 1つのテーブルに外部キー(一意制約) | 一意制約が欠けていると重複が許可される。 |
| 1対多 | 親クラス内のリストコレクション | 子テーブルの外部キー | 外部キーにインデックスが欠けているとクエリが遅くなる。 |
| 多対多 | リンククラスまたは関連 | 2つの外部キーを持つ結合テーブル | 結合テーブルが省略されるとデータ損失が発生する。 |
| 継承 | extendsキーワードまたは矢印 | NULLを含む単一のテーブル、または複数のテーブル | 単一テーブルのスパース性、または複数テーブルでの複雑な結合。 |
📝 アライメントのためのベストプラクティス
将来の摩擦を最小限に抑えるため、チームは論理モデルと物理モデルの整合性を最優先する戦略を採用すべきである。これは技術だけでなく、コミュニケーションとプロセスを含む。
- スキーマ優先アプローチ:アプリケーションコードを書く前にデータベーススキーマを定義する。これにより、ストレージ層が制約を決定し、コードがそれに適応するようになる。
- コード優先アプローチ:まずクラスを定義し、その後スキーマを生成する。開発には速いが、後で最適化が難しい非効率な物理構造を作り出すリスクがある。
- ドキュメント:クラスのプロパティとデータベースのカラムを対応付ける動的なドキュメントを維持する。これにより、開発者およびデータベース管理者にとって単一の真実の情報源となる。
- レビューのサイクル:コードレビューのプロセスにデータベーススキーマのレビューを含める。マイグレーションスクリプトがクラスの変更と一致していることを確認せずに、コードをマージしてはならない。
🛠️ レガシーシステムの対応
すべてのプロジェクトが白紙から始まるわけではない。多くの組織は、現在のクラス図と一致しないレガシーデータベースに対処しなければならない。この文脈でのリファクタリングには注意が必要である。
- ストレンジャーフィグパターン:古いシステムを稼働状態のまま、新しい機能を段階的に新しいスキーマに移行する。これにより、既存の統合を壊すことなくクラス図を進化させることができる。
- ビューとステージング:新しいクラス図の形式に合わせたデータの表示を可能にするために、データベースのビューを作成する。これにより、基盤となるテーブルを即座に変更せずに済む。
- 段階的マイグレーション:データをバッチ単位で移行する。次のバッチに進む前に、各バッチの整合性を確認する。これにより、移行中にデータ損傷のリスクを最小限に抑えることができる。
🚀 未来へ向けて
クラス図とデータベーススキーマの間には、ソフトウェア工学における本質的な課題が存在する。これは、コンピュータが論理を処理する方法と情報の保存方法との根本的な違いから生じる。完全にこの摩擦を排除する解決策は存在しないが、効果的に管理するための戦略は存在する。
継承、関係性、データ型、命名規則の微細な点を理解することで、チームはエラーの発生頻度を低下させることができる。定期的な監査と自動化ツールの活用により、時間の経過とともに同期を維持することができる。目標はデータベースをコードと完全に同じように見せるのではなく、両者のマッピングが透明で、一貫性があり、パフォーマンスが良いことを保証することである。物理的なストレージが論理設計と一致しているとき、開発はより予測可能になり、システムは負荷下でも安定した状態を保つことができる。