










В современной архитектуре программного обеспечения разрыв между объектно-ориентированной моделью, используемой в коде приложения, и реляционной моделью, используемой для постоянного хранения данных, является постоянной проблемой. Разработчики часто сталкиваются с ситуациями, когда визуальное представление структур данных на диаграмме классов значительно отличается от физической структуры таблиц и столбцов в схеме базы данных. Это расхождение не является лишь внешним; оно представляет собой фундаментальное архитектурное противоречие, которое может привести к проблемам целостности данных, узким местам производительности и увеличению затрат на сопровождение. Понимание коренных причин этих несоответствий является ключевым для создания надежных, масштабируемых систем.
Когда диаграмма классов не соответствует лежащей в основе схеме базы данных, возникает несоответствие импеданса. Этот термин описывает совокупность трудностей, присущих использованию объектно-ориентированных языков программирования для решения задач, существующих в среде реляционной базы данных. В то время как мир объектов работает с экземплярами, методами и наследованием, мир баз данных опирается на множества, строки и внешние ключи. Преодоление этого разрыва требует осознанных решений при проектировании и строгой проверки.
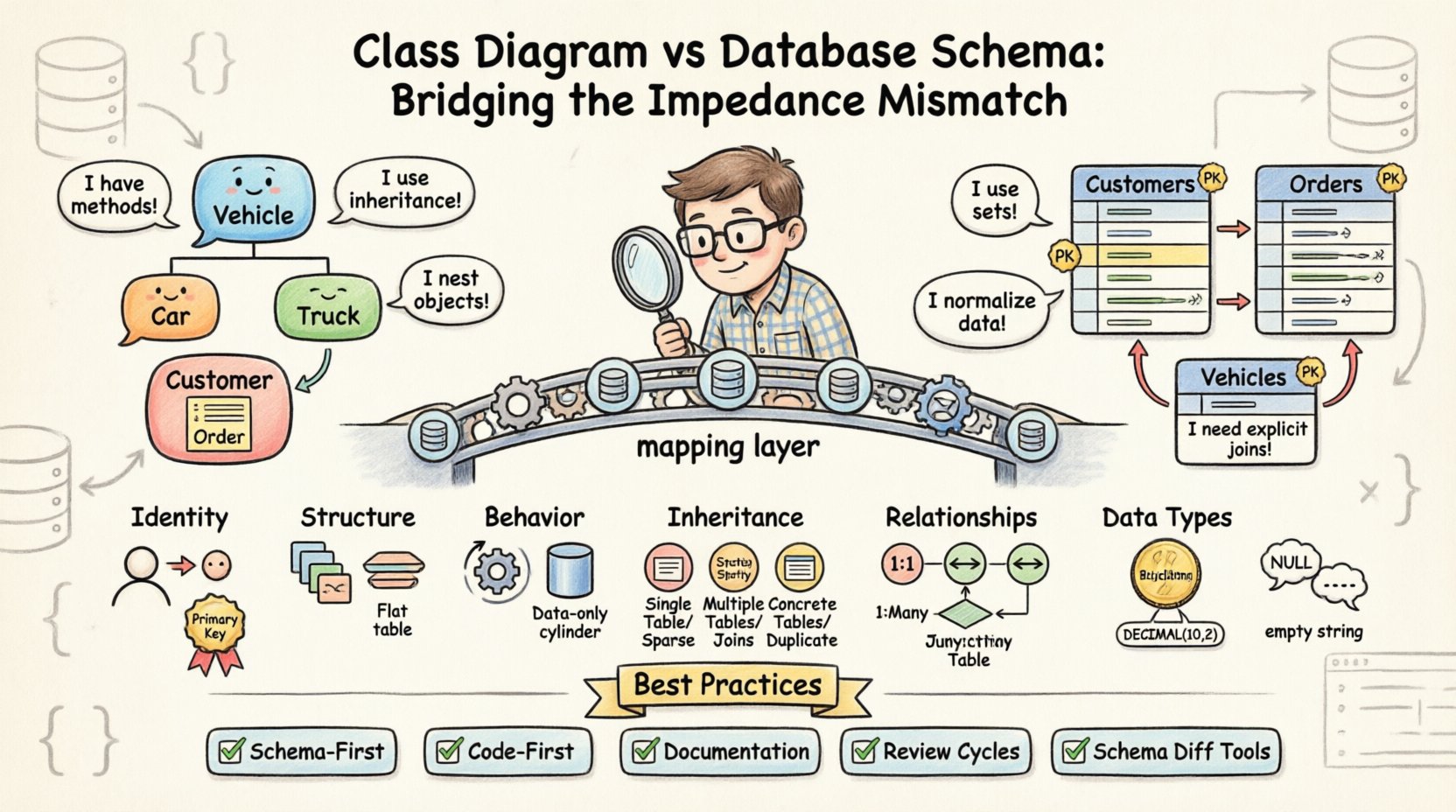
🔄 Основное противоречие: объекты против таблиц
Фундаментальное различие заключается в философии хранения данных. Объектно-ориентированные классы инкапсулируют состояние и поведение вместе. В противоположность этому, реляционные базы данных нормализуют данные для уменьшения избыточности. Это различие создает несколько конкретных областей, где две модели испытывают трудности при синхронизации.
- Идентичность:Объекты идентифицируются по ссылке в памяти или уникальному идентификатору объекта во время выполнения. Базы данных используют первичные ключи, часто автоинкрементирующиеся целые числа или UUID, которые существуют независимо от жизненного цикла приложения.
- Структура:Класс может содержать сложные вложенные объекты, коллекции и циклические ссылки. Таблица базы данных не может нативно хранить вложенный объект без его выравнивания или создания отдельной таблицы.
- Поведение:Классы содержат методы, манипулирующие данными. Таблицы базы данных содержат только данные; вся логика должна обрабатываться с помощью хранимых процедур или за пределами слоя базы данных.
Когда разработчики пытаются напрямую сопоставить эти две парадигмы без тщательной абстракции, возникают ошибки. Уровень отображения часто выступает в роли переводчика, но ни один переводчик не идеален. Нюансы логики, обработка null-значений и преобразование типов часто теряются при переводе.
🏗️ Структурные несоответствия при отображении
Одной из наиболее распространенных причин несоответствий является способ обработки отношений между сущностями. На диаграмме классов отношения часто изображаются простыми линиями, указывающими на ассоциации. В схеме базы данных эти ассоциации требуют явных ограничений внешнего ключа и часто промежуточных таблиц соединения.
Иерархии наследования
Объектно-ориентированные системы процветают благодаря наследованию. Класс Vehicle может иметь подклассы, такие как Car и Truck. Это позволяет реализовать полиморфизм и повторное использование кода. Однако реляционные базы данных не поддерживают наследование нативно. Чтобы смоделировать это, инженеры должны выбирать между конкретными стратегиями, каждая из которых имеет свои компромиссы.
- Таблица на иерархию: Одна таблица хранит все данные для родительского класса и всех подклассов. Это просто, но приводит к разреженным столбцам и null-значениям при использовании полей, специфичных для подкласса.
- Таблица на подкласс: Каждый класс получает свою собственную таблицу. Таблица родителя хранит общие атрибуты, а таблицы потомков — специфические, связанные внешним ключом. Это увеличивает сложность операций соединения, необходимых для получения полного объекта.
- Таблица на конкретный класс: Каждый конкретный класс получает полную таблицу, содержащую все атрибуты. Это исключает необходимость соединений, но требует дублирования общих данных в нескольких таблицах.
Если диаграмма классов показывает четкую иерархию наследования, но схема базы данных использует одну плоскую таблицу, схема не соответствует логической модели. Это может привести к путанице при сопровождении, поскольку разработчики могут ожидать наличие определенных столбцов, которых не существует из-за стратегии выравнивания.
Ассоциация и агрегация
Рассмотрим Клиент класс с коллекцией Заказ объектов. На диаграмме классов это отношение один ко многим. В базе данных это представлено столбцом внешнего ключа в таблице Заказы , ссылающейся на таблицу Клиенты . Однако направление отношения часто является источником несоответствий.
- Соотношения многие ко многим: Диаграмма классов может показать
СтудентиКурссвязанными много к много. База данных требует третьей таблицы, часто называемой таблицей соединения или мостовой таблицей, для разрешения этого. Если схема опускает эту таблицу, отношение не может быть обеспечено. - Мощность: Диаграмма классов может указывать на необязательное отношение (0..*). Схема базы данных должна отражать это с помощью внешних ключей, допускающих NULL. Если схема налагает ограничение NOT NULL, это противоречит определению класса.
- Каскадное удаление: В коде удаление родительского объекта может автоматически удалять дочерние объекты. В базе данных для этого требуются правила каскадного удаления. Если они не настроены, остаются орфанные записи, нарушая целостность данных.
🛡️ Целостность данных и несоответствия типов
Помимо структуры, фактические типы данных, определённые в классе, часто не совпадают с типами столбцов базы данных. Хотя современные системы предлагают обширные возможности сопоставления, крайние случаи часто вызывают проблемы.
Ограничения допустимости NULL
В объектно-ориентированных языках поле по умолчанию часто допускает значение NULL, если явно не инициализировано. В реляционных базах данных ограничение NOT NULL — это оптимизация производительности и целостности. Несоответствие здесь приводит к исключениям во время выполнения.
- Значения по умолчанию: Класс может предполагать, что строковое поле по умолчанию пустая строка. База данных может по умолчанию задать ему значение NULL. Код, ожидающий пустую строку, вылетит, если получит NULL.
- Валидация: Валидация на уровне приложения может разрешать полю быть NULL. Схема базы данных отвергает это. Это создаёт конфликт между бизнес-логикой и слоем хранения данных.
Точность и масштаб числовых значений
Финансовые данные требуют высокой точности. Класс может использовать BigDecimal или Десятичный тип для обработки валюты. База данных должна поддерживать соответствующий тип столбца с определенной точностью и масштабом.
- Обрезка: Если столбец базы данных определен как
DECIMAL(10, 2)но логика приложения пытается сохранитьDECIMAL(10, 4), данные будут потеряны бесшумно или с ошибкой. - Float против Decimal: Использование типов с плавающей точкой для денег — распространённая ошибка. Хотя класс может использовать
doubleдля производительности, база данных должна обеспечивать точные вычисления, чтобы предотвратить ошибки округления в бухгалтерском учёте.
🏷️ Соглашения об именовании и идентичность
Согласованность в именовании имеет важное значение для поддержки. Однако соглашения, используемые в языках программирования, часто отличаются от тех, что используются в системах управления базами данных.
Snake_case против CamelCase
Java и C# обычно используют camelCase для свойств классов и имён полей. Многие реляционные базы данных предпочитают snake_case для имён таблиц и столбцов. Хотя инструменты отображения часто автоматически обрабатывают такое преобразование, ручное создание схемы может нарушить это правило.
- Регистр символов: Некоторые базы данных чувствительны к регистру, а другие — нет. Столбец с именем
FirstNameв базе данных может быть запрошен какfirstnameв коде, что приводит к ошибкам в зависимости от конфигурации сервера. - Зарезервированные слова: Свойства классов могут использовать имена, которые являются зарезервированными ключевыми словами в языке базы данных, например
OrderилиUser. Для них требуется использование кавычек или псевдонимов, что усложняет генерацию запросов.
Первичные и внешние ключи
Выбор стратегии первичного ключа — еще одна распространенная проблема. Классы часто полагаются на естественные ключи (например, имя пользователя или электронный адрес) или заменяющие ключи (например, авто-генерируемый ID).
- Естественные ключи:Использование делового значения в качестве первичного ключа может сделать схему жесткой. Если бизнес-правило меняется (например, электронный адрес изменяется), ссылки внешнего ключа должны быть обновлены повсюду.
- Заменяющие ключи:Использование автоинкрементного ID безопаснее при соединениях, но вводит дополнительный столбец, не имеющий семантического значения в бизнес-логике.
⚡ Компромиссы производительности
Проектирование схемы, соответствующей диаграмме классов, часто игнорирует последствия для производительности. Теоретическая корректность не всегда равна операционной эффективности.
Нормализация против денормализации
Диаграммы классов часто отражают нормализованные структуры данных, чтобы избежать избыточности. Однако производительность базы данных иногда выигрывает от денормализации, чтобы сократить количество соединений, необходимых при операциях чтения.
- Сложность соединений:Сложерная иерархия классов может потребовать нескольких соединений для получения одного объекта. В системах с высокой нагрузкой это может значительно снизить время отклика.
- Кэширование:Денормализованные данные можно кэшировать проще. Если схема слишком нормализована, прикладной слой должен выполнять сложную логику восстановления, что аннулирует преимущества кэширования.
Стратегии индексирования
Индексы определяются на уровне базы данных для ускорения запросов, но редко отображаются на диаграмме классов. Отсутствие определений индексов при проектировании схемы может привести к медленным запросам.
- Индексы внешних ключей:Столбцы внешних ключей, как правило, должны быть проиндексированы, чтобы ускорить операции соединения. Если схема не включает эти индексы, поиск по связанным данным будет сканировать целые таблицы.
- Шаблоны поиска: Если приложение часто ищет по определенному атрибуту, требуется индекс базы данных. Если диаграмма классов выделяет этот атрибут, но схема его не индексирует, производительность пострадает.
🔍 Обнаружение и устранение несоответствий
Определение того, где схема расходится с моделью, — первый шаг к решению. Этот процесс требует комбинации автоматизированных инструментов и ручной проверки.
Инструменты сравнения схем
Автоматизированные инструменты сравнения могут выделить различия между ожидаемым состоянием (выведенным из диаграммы классов или кода) и фактическим состоянием (физической базы данных).
- Обнаружение изменений: Эти инструменты могут выявить отсутствующие столбцы, измененные типы данных или удаленные ограничения.
- Скрипты миграции: Они могут генерировать необходимый SQL для приведения схемы в соответствие с моделью, снижая количество ошибок, вызванных вручную.
Ручная проверка
Автоматизация полезна, но для сложной логики необходима ручная проверка. Проверяющие должны убедиться в следующем:
- Все ли поля класса представлены столбцами базы данных?
- Совпадают ли типы данных точно, включая длину и точность?
- Ограничены ли отношения правильно с помощью внешних ключей?
- Согласованы ли соглашения об именовании повсеместно?
Распространённые сценарии отображения и потенциальные проблемы
| Сценарий отображения | Представление диаграммы классов | Представление схемы базы данных | Потенциальная проблема |
|---|---|---|---|
| Один к одному | Одна линия, соединяющая два класса | Внешний ключ в одной таблице (уникальное ограничение) | Отсутствие уникального ограничения позволяет дублирование. |
| Один ко многим | Список коллекции в родительском классе | Внешний ключ в дочерней таблице | Отсутствие индекса по внешнему ключу замедляет запросы. |
| Многие ко многим | Класс-связь или ассоциация | Таблица-связка с двумя внешними ключами | Пропуск таблицы-связки приводит к потере данных. |
| Наследование | Ключевое слово extends или стрелка | Одна таблица с NULL-значениями ИЛИ несколько таблиц | Разреженность в одной таблице или сложные соединения в нескольких. |
📝 Лучшие практики выравнивания
Чтобы минимизировать будущие трудности, команды должны внедрять стратегии, которые ставят во главу угла согласованность между логической и физической моделями. Это требует коммуникации и процессов, а не только технологий.
- Подход «схема первая»: Определите схему базы данных до написания кода приложения. Это гарантирует, что уровень хранения определяет ограничения, а код должен адаптироваться к ним.
- Подход «код первая»: Сначала определите классы, а затем сгенерируйте схему. Это быстрее для разработки, но несёт риск создания неэффективной физической структуры, которую будет сложно оптимизировать позже.
- Документация: Поддерживайте живой документ, в котором отображаются свойства классов и столбцы базы данных. Это служит единственным источником истины для разработчиков и администраторов баз данных.
- Циклы проверки: Включите проверку схемы базы данных в процесс код-ревью. Никакой код не должен быть объединён без проверки соответствия скриптов миграции изменениям в классах.
🛠️ Работа с унаследованными системами
Не все проекты начинаются с чистого листа. Многим организациям приходится работать с унаследованными базами данных, которые не соответствуют текущим диаграммам классов. Рефакторинг в этой среде требует осторожности.
- Паттерн «Стреляющий фиг»: Постепенно переносите новую функциональность в новую схему, пока старая система остаётся работоспособной. Это позволяет диаграмме классов развиваться без нарушения существующих интеграций.
- Представления и промежуточные этапы: Создавайте представления базы данных, чтобы отображать данные в формате, соответствующем новой диаграмме классов, не изменяя при этом базовые таблицы сразу.
- Постепенная миграция: Переносите данные порциями. Проверяйте целостность после каждой порции перед переходом к следующей. Это минимизирует риск повреждения данных во время перехода.
🚀 Вперёд
Разрыв между диаграммой классов и схемой базы данных — это неизбежный вызов в инженерии программного обеспечения. Он возникает из фундаментальных различий между тем, как компьютеры обрабатывают логику, и тем, как они хранят информацию. Нет идеального решения, полностью устраняющего эту несогласованность, но существуют стратегии для эффективного управления ею.
Понимая нюансы наследования, отношений, типов данных и соглашений об именовании, команды могут снизить частоту ошибок. Регулярная проверка и использование автоматизированных инструментов помогают поддерживать синхронизацию с течением времени. Цель не в том, чтобы база данных выглядела точно как код, а в обеспечении прозрачного, последовательного и производительного отображения между ними. Когда физическое хранение данных согласуется с логическим дизайном, разработка становится более предсказуемой, а система остаётся стабильной под нагрузкой.