











在软件架构和数据建模的领域中,很少有概念能像实体之间的关系那样具有重要性。在设计系统时,理解对象之间的交互方式,与定义对象本身同样关键。这种交互通过类图多重性这一符号来正式表达,它规定了两个类之间的数量关联。无论你是绘制数据库模式还是构建面向对象的代码库,这里的清晰性都能在问题出现之前防止架构债务的积累。
多重性定义了某一类实例可以与另一类实例关联的数量限制。它回答了根本性问题:一个用户能否拥有多个个人资料?一个订单能否属于多个客户?这些区别决定了数据的流动方式以及应用程序的完整性。本指南将深入探讨核心基数——1:1、1:N 和 N:N,详细分析它们的实现方式、影响以及常见陷阱。
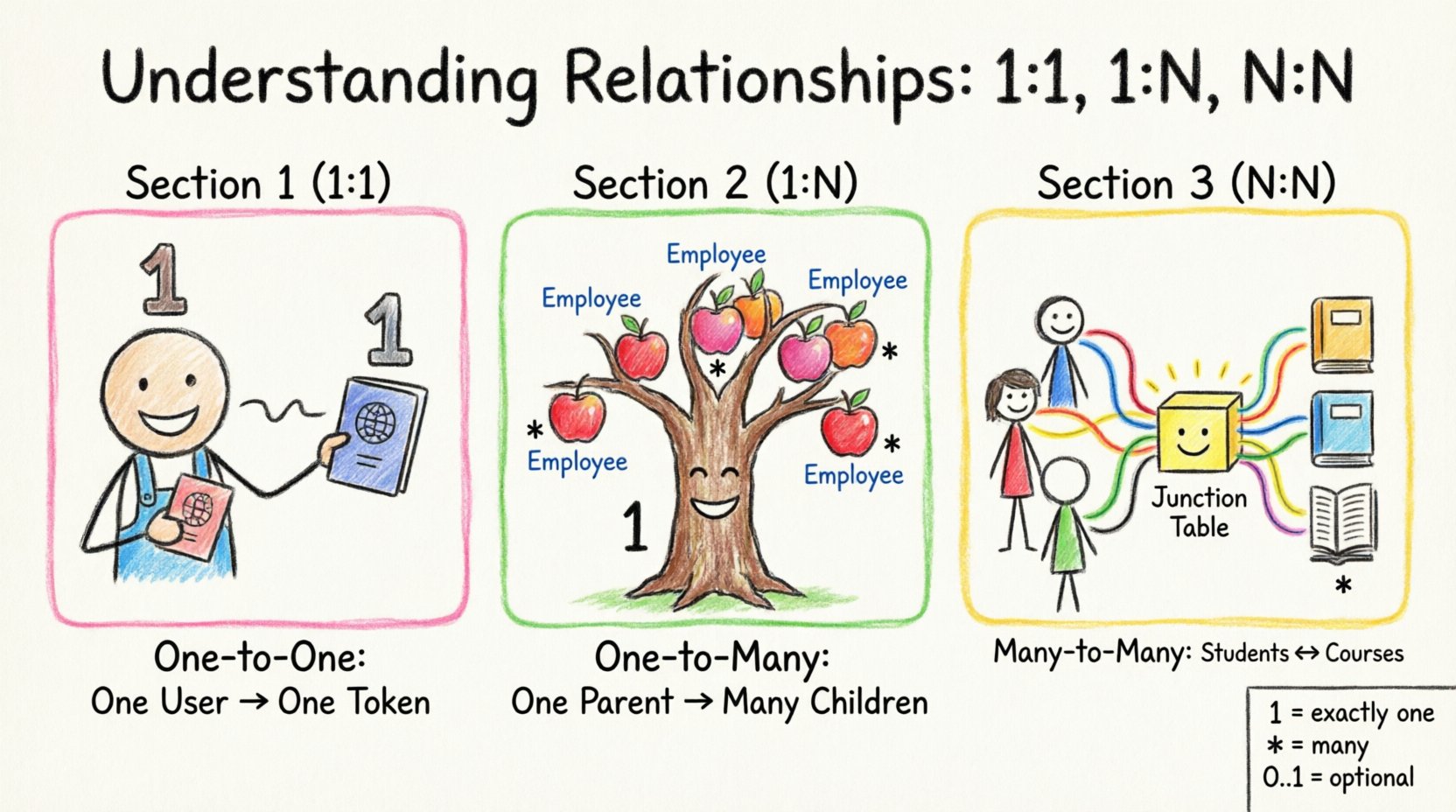
理解基础:符号与术语 🧩
在深入探讨特定关系类型之前,必须先建立统一建模语言(UML)和通用数据建模中使用的术语体系。多重性不仅仅是计数,更在于定义规则。
- 基数: 一个类的实例可以参与关系的数量。通常用数字如
1,*,或范围如0..1. - 可选性: 一个类的实例是否必须参与该关系。例如,每个员工都需要一个经理吗?
- 关联: 这一连接本身,表示类之间的结构性关系。
当你查看类图时,会看到连接方框的线条。在这些线条附近,小数字或符号表示多重性。这些符号如同契约。如果系统逻辑违反了这些契约,数据就会变得不一致。理解这种符号是迈向稳健设计的第一步。
一对一关系(1:1) 🔗
一对一关系是标准关联中最受限制的一种。它意味着对于类 A 的每一个实例,最多只有一个类 B 的实例与之对应,反之亦然。这通常用符号1表示在关联线的两端。
何时使用 1:1 关联
当两个概念本质上是同一实体的不同视角,或当关联是排他且永久性时,这种关系类型适用。
- 认证令牌: 用户账户在同一时间只能拥有一个有效的会话令牌。如果用户再次登录,之前的令牌将被失效。
- 身份文件: 护照仅颁发给一个特定的公民,而一个公民在同一时间只能持有一本主要护照。
- 配置设置:特定的应用程序实例通常只有一个Configuration对象来保存其运行时参数。
实现注意事项
实现一对一关系需要仔细关注外键和数据库约束。在关系型数据库中,通常通过在一个表中放置一个外键来实现,该外键引用另一个表的主键。
- 数据库外键: 您必须添加一个
外键约束以确保引用完整性。这可以防止出现孤立记录。 - 唯一性约束: 为了严格强制“一”端,包含外键的列必须具有一个
唯一约束。这确保没有两行可以指向同一个父级。 - 代码引用: 在面向对象的代码中,这通常表现为对单个对象的直接引用,而不是集合。一个
User类可能有一个名为Profile的属性,其类型为Profile,而不是List<Profile>.
一对多关系(1:N)🌳
一对多关系是企业系统中最常见的关联。在这里,Class A 的一个实例与零个或多个 Class B 的实例相关联。然而,每个 Class B 的实例都恰好与一个 Class A 的实例相关联。表示法通常在一端显示 1,在另一端显示 *(或 0..*)
常见场景
此模式描述了层级数据,其中父级拥有多个子级。
- 订单和明细项:一个订单包含多个明细项,但每个明细项仅属于一个订单。
- 部门和员工:一个部门雇佣多名员工,但一名员工仅被分配到一个部门(在简单结构中)。
- 类别和产品:一个产品类别包含多个产品,但一个产品仅属于一个特定类别。
数据结构化
在关系型数据库中实现1:N关系很简单,但在内存模型中需要特殊处理。
- 外键位置: 外键位于“多”方(子表)中。订单表将有一个
order_id列,用于链接到明细项表。 - 集合管理: 在“一”方(父对象)中,通常维护一个集合。一个
Customer对象将包含一个订单对象的列表或数组。Order对象。 - 性能影响:如果集合很大,获取“多”方的数据可能会变得昂贵。通常采用延迟加载,在访问时才获取子对象,从而减少初始查询开销。
处理级联删除
在1:N设计中,一个关键决策是当父级被删除时会发生什么。如果你删除一个部门,是否也要删除所有员工?通常答案是否定的,但系统必须妥善处理。
- 级联删除:当父级被删除时,自动删除所有子记录。适用于临时数据,如订单日志。
- 限制删除:如果存在子记录,则禁止删除父记录。适用于核心数据,如产品。
- 置为空:将子记录中的外键设置为null。要求子记录允许null值。
多对多关系 (N:N) 🕸️
多对多关系是三种关系中最复杂的。当类A的实例可以与类B的多个实例相关联,且类B的实例也可以与类A的多个实例相关联时,就会出现这种情况。符号表示*(或0..*)出现在两端。
现实世界中的例子
这种关系常见于涉及标签、角色或注册的场景中。
- 学生和课程:一个学生可以注册多门课程,一门课程也有多个学生。
- 作者和书籍:一位作者撰写多本书籍,而一本书可以有多个作者(合著者)。
- 技能和员工:一名员工拥有多种技能,而一种技能也被多名员工拥有。
连接实体解决方案
在关系型数据库中直接实现N:N关系是不可能的。一个单一的外键无法在不产生歧义的情况下双向链接两个表。解决方案是引入一个连接表(或关联实体)。
这个中间表将N:N关系分解为两个1:N关系。
- 结构: 连接表包含两个相关表的主键作为外键。
- 附加数据: 与简单的链接不同,连接表可以拥有自己的属性。例如,学生和课程之间的关联可能需要一个
成绩或注册日期. - 复合键: 连接表的主键通常是由两个外键组成的复合键,以确保配对的唯一性。
面向对象的实现
在代码中,管理N:N关系需要保持双向一致性。如果你将一门课程添加到学生中,你也必须将该学生添加到这门课程中。
- 同步:应创建辅助方法来管理这些链接。一个
Student.addCourse(课程 c)方法应自动将学生添加到课程的列表中。 - 内存使用: 由于数据在两个集合(学生列表和课程列表)中重复,内存使用量增加。如果删除了链接,请确保垃圾回收能处理孤立的引用。
基数与可选性:一个关键区别 ⚖️
在讨论多重性时,必须区分数量多少和是否必需。这两者常被混淆,但代表不同的规则。
- 最小基数: 所需的最少实例数量。通常为0或1。
- 最大基数: 允许的最大实例数量。通常为1或多个(*)。
- 零个或一个(0..1): 该关系是可选的。该实例可能存在,也可能不存在。
- 一个或多个(1..*): 该关系是强制的。该实例必须存在,并且可以有多个。
考虑一个员工 和 经理 的关系。一名员工必须有一位经理(1..1),但一位经理在特定时刻可能不管理任何人(0..*)。理解这些细微差别有助于实现精确的数据库约束和验证逻辑。
将设计转化为实现 🛠️
一旦类图确定,转向实际代码和存储就需要针对每种关系类型制定特定策略。
数据库模式设计
物理模式是系统中最僵化的一部分。这里的更改成本很高。
- 规范化: 确保你的设计遵循规范化规则(通常到3NF为止)。冗余数据通常源于对关系的误解。
- 索引: 外键列应建立索引。这能显著加快连接操作和约束检查。
- 数据类型: 确保主键的数据类型与外键完全匹配。类型不匹配会导致运行时错误。
应用层逻辑
代码层是业务规则强制实施关系的地方。
- 验证: 在保存对象之前,验证关系约束是否满足。例如,不允许学生注册已满的课程。
- 事务管理: 在创建或更新相关对象时,将操作包裹在事务中。这确保如果关系的某一部分失败,整个更改都会回滚。
- API 响应: 通过 API 暴露数据时,决定相关对象嵌套的深度。在单个响应中返回包含所有订单的完整客户对象可能导致性能瓶颈。
常见陷阱与反模式 🚫
即使经验丰富的设计师在定义多重性时也会犯错。及早识别这些模式可以节省大量后期重构时间。
- 假设 N:N 总是必要的: 如果两个实体看似有关联,需检查它们是否真的需要直接连接。如果关系具有方向性,通常 1:N 已经足够。
- 忽略可选性: 当关系实际上是可选的(0..1)时,却设计为强制链接(1..1),会导致数据录入错误和系统僵化。
- 循环依赖: 当类 A 引用类 B,而类 B 又引用类 A 时,序列化和内存管理可能变得复杂。在遍历算法中使用深层递归时需谨慎。
- 过度设计的连接表: 如果关系简单且不需要自身属性,就不应创建连接表。有时,一个外键就足够了。
关系类型对比 📊
为总结差异和权衡,可参考这三种主要基数的概述。
| 特性 | 一对一(1:1) | 一对多(1:N) | 多对多(N:N) |
|---|---|---|---|
| 表示法 | 1 — 1 | 1 — * | * — * |
| 数据库实现 | 带唯一约束的外键 | 子表中的外键 | 连接表(关联实体) |
| 代码结构 | 单个对象引用 | 对象集合/列表 | 集合的集合 |
| 查询复杂度 | 低 | 中等 | 高(需要连接) |
| 灵活性 | 低(严格) | 高 | 非常高 |
数据完整性最终考量 ✅
软件系统的稳定性在很大程度上依赖于其关系的正确性。在定义多重性时,您实际上是在为数据设定交互规则。一个定义清晰的类图就像一份蓝图,能够使数据库、代码和业务逻辑保持一致。
始终验证您的假设。绘制图表,实现一个原型,并检查数据是否自然流动。如果您发现自己不断添加变通方法,以将数据塞入看似 N:N 的 1:N 结构中,那么是时候重新审视设计了。
通过遵循这些原则,您可以确保系统保持可扩展性、可维护性和逻辑一致性。在正确识别 1:1、1:N 和 N:N 关系上投入的努力,将在项目生命周期内带来更少的错误和更清晰的代码结构回报。
关键要点
- 符号很重要: 使用标准符号(1、0..1、*)以清晰传达意图。
- 数据库对齐: 确保您的模式支持图表,而无需强行使用别扭的变通方法。
- 可选性是关键: 区分“必须存在”和“可能不存在”,以避免过于僵化的约束。
- 管理复杂性: 对于 N:N 关系,使用连接表以保持引用完整性。
- 尽早验证: 在设计阶段检查关系,以防止架构债务。