











In der modernen Softwarearchitektur ist die Diskrepanz zwischen dem objektorientierten Modell, das im Anwendungscode verwendet wird, und dem relationalen Modell, das bei der dauerhaften Speicherung eingesetzt wird, eine anhaltende Herausforderung. Entwickler stoßen häufig auf Situationen, in denen die visuelle Darstellung von Datenstrukturen im Klassendiagramm erheblich von der physischen Anordnung von Tabellen und Spalten im Datenbank-Schema abweicht. Diese Diskrepanz ist nicht nur oberflächlich; sie stellt eine grundlegende architektonische Spannung dar, die zu Datenintegritätsproblemen, Leistungsbottlenecks und erhöhten Wartungskosten führen kann. Das Verständnis der Ursachen dieser Abweichungen ist entscheidend für die Entwicklung robuster, skalierbarer Systeme.
Wenn ein Klassendiagramm nicht mit dem zugrundeliegenden Datenbank-Schema übereinstimmt, entsteht eine Impedanzanpassungsproblematik. Dieser Begriff beschreibt die Reihe von Schwierigkeiten, die inhärent darin liegen, objektorientierte Programmiersprachen einzusetzen, um Probleme zu lösen, die in einer relationalen Datenbankumgebung bestehen. Während die Welt der Objekte auf Instanzen, Methoden und Vererbung basiert, stützt sich die Datenbankwelt auf Mengen, Zeilen und Fremdschlüssel. Die Brücke zwischen diesen beiden Welten erfordert bewusste Gestaltungsentscheidungen und strenge Validierung.
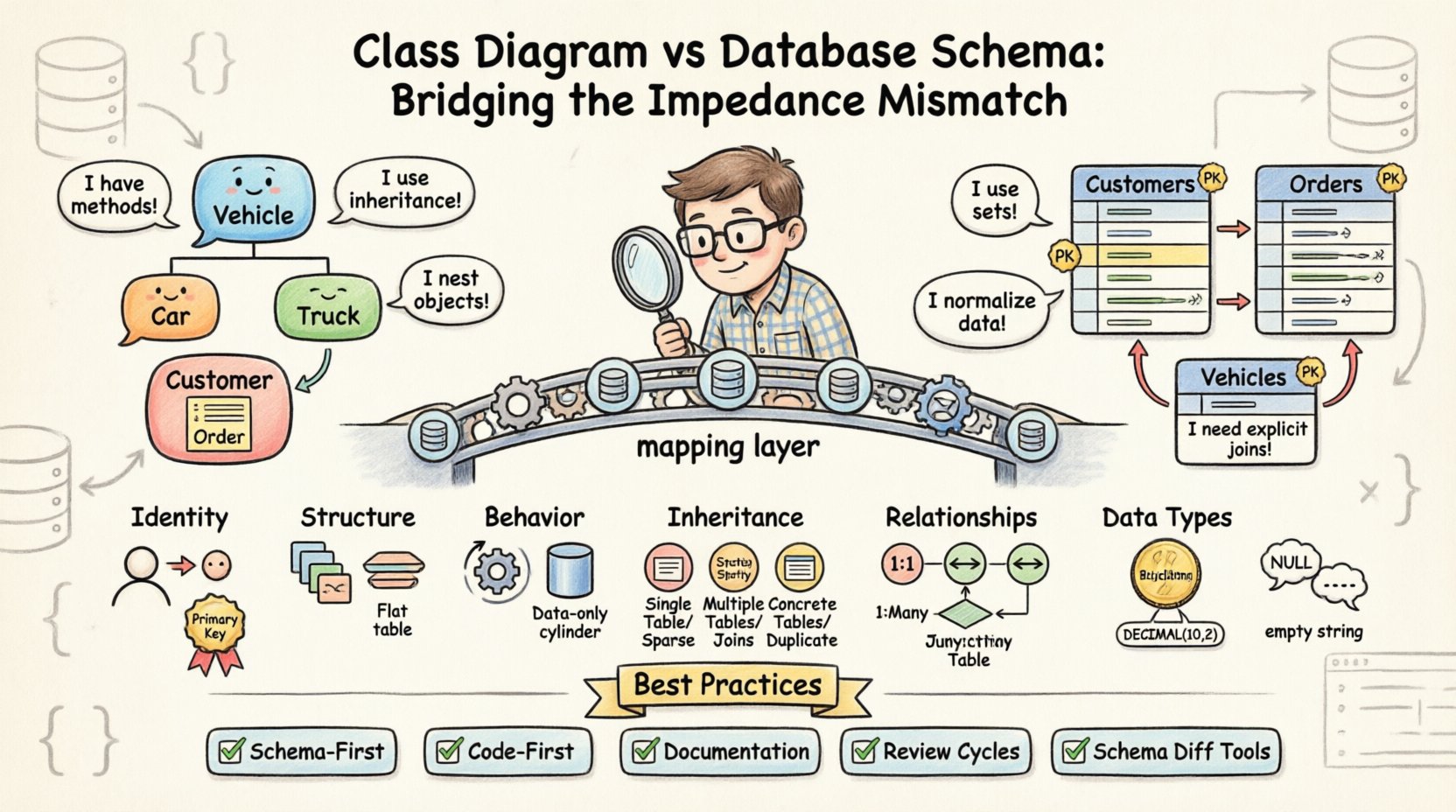
🔄 Die zentrale Spannung: Objekte vs. Tabellen
Der grundlegende Unterschied liegt in der Philosophie der Datenhaltung. Objektorientierte Klassen kapseln Zustand und Verhalten gemeinsam. Im Gegensatz dazu normalisiert relationale Datenbanken Daten, um Redundanz zu minimieren. Diese Divergenz erzeugt mehrere spezifische Bereiche, in denen die beiden Modelle Schwierigkeiten haben, synchronisiert zu werden.
- Identität:Objekte werden zur Laufzeit anhand eines Speicherreferenz oder eines eindeutigen Objekt-Identifikators identifiziert. Datenbanken verwenden Primärschlüssel, oft automatisch hochzählende Ganzzahlen oder UUIDs, die unabhängig vom Lebenszyklus der Anwendung existieren.
- Struktur:Eine Klasse kann komplexe verschachtelte Objekte, Sammlungen und zirkuläre Referenzen enthalten. Eine Datenbanktabelle kann ein verschachteltes Objekt nicht natively speichern, ohne es zu flach zu legen oder eine separate Tabelle zu erstellen.
- Verhalten:Klassen enthalten Methoden, die Daten manipulieren. Datenbanktabellen enthalten nur Daten; jegliche Logik muss über gespeicherte Prozeduren oder außerhalb der Datenbankebene behandelt werden.
Wenn Entwickler versuchen, diese beiden Paradigmen ohne sorgfältige Abstraktion direkt zu verknüpfen, treten Fehler auf. Die Abbildungsschicht fungiert oft als Übersetzer, aber kein Übersetzer ist perfekt. Feinheiten in der Logik, der Behandlung von Nullwerten und der Typumwandlung gehen häufig bei der Übersetzung verloren.
🏗️ Strukturelle Diskrepanzen bei der Abbildung
Eine der häufigsten Quellen für Abweichungen betrifft die Art und Weise, wie Beziehungen zwischen Entitäten behandelt werden. In einem Klassendiagramm werden Beziehungen oft als einfache Linien dargestellt, die Assoziationen anzeigen. In einem Datenbank-Schema erfordern diese Assoziationen explizite Fremdschlüsselbeschränkungen und oft dazwischenliegende Verknüpfungstabellen.
Vererbungshierarchien
Objektorientierte Systeme profitieren von Vererbung. Eine FahrzeugKlasse könnte Unterklassen wie Auto und LKW. Dies ermöglicht Polymorphismus und Code-Wiederverwendung. Allerdings unterstützen relationale Datenbanken Vererbung nicht nativ. Um dies zu modellieren, müssen Ingenieure zwischen spezifischen Strategien wählen, wobei jede Strategie ihre eigenen Kompromisse birgt.
- Tabelle pro Hierarchie: Eine einzelne Tabelle speichert alle Daten für die Elternklasse und alle Unterklassen. Dies ist einfach, führt aber zu spärlichen Spalten und Nullwerten, wenn feldspezifische Attribute der Unterklassen verwendet werden.
- Tabelle pro Unterklasse: Jede Klasse erhält ihre eigene Tabelle. Die Eltern-Tabelle speichert gemeinsame Attribute, während die Kindtabellen spezifische Attribute enthalten, die über einen Fremdschlüssel verknüpft sind. Dies erhöht die Komplexität der Joins, die erforderlich sind, um ein vollständiges Objekt abzurufen.
- Tabelle pro konkrete Klasse: Jede konkrete Klasse erhält eine vollständige Tabelle, die alle Attribute enthält. Dies vermeidet Joins, erfordert aber die Duplizierung gemeinsamer Daten über mehrere Tabellen.
Wenn das Klassendiagramm eine klare Vererbungshierarchie zeigt, aber das Datenbank-Schema eine einzelne flache Tabelle verwendet, stimmt das Schema nicht mit dem logischen Modell überein. Dies kann zu Verwirrung bei der Wartung führen, da Entwickler bestimmte Spalten erwarten könnten, die aufgrund der Flachhaltungsstrategie nicht existieren.
Assoziation und Aggregation
Betrachten Sie eine Kunde Klasse mit einer Sammlung von Bestellung Objekten. In der Klassendiagramm ist dies eine Eins-zu-Viele-Beziehung. In der Datenbank wird dies durch eine Fremdschlüsselspalte in der Bestellungen Tabelle dargestellt, die auf die Kunden Tabelle verweist. Allerdings liegt der häufigste Fehler in der Richtung der Beziehung.
- Viele-zu-Viele-Beziehungen: Ein Klassendiagramm könnte zeigen, dass
StudentundKursdurch eine viele-zu-viele-Beziehung verbunden sind. Die Datenbank erfordert eine dritte Tabelle, die oft als Verbindungstabelle oder Brückentabelle bezeichnet wird, um diese Beziehung aufzulösen. Wenn das Schema diese Tabelle auslässt, kann die Beziehung nicht durchgesetzt werden. - Kardinalität: Ein Klassendiagramm könnte eine optionale Beziehung (0..*) anzeigen. Das Datenbankschema muss dies mit nullable Fremdschlüsseln widerspiegeln. Wenn das Schema eine NOT NULL-Beschränkung durchsetzt, widerspricht dies der Klassendefinition.
- Kaskadenlöschungen: Im Code könnte das Löschen eines übergeordneten Objekts automatisch die untergeordneten Objekte entfernen. In der Datenbank erfordert dies kaskadenartige Löschregeln. Wenn diese nicht konfiguriert sind, bleiben verwaiste Datensätze bestehen und verletzen die Datenintegrität.
🛡️ Datenintegrität und Typenkonflikte
Abgesehen von der Struktur stimmen die tatsächlich in der Klasse definierten Datentypen oft nicht mit den Datentypen der Datenbankspalten überein. Obwohl moderne Systeme umfangreiche Abbildungsmöglichkeiten bieten, führen häufig Sonderfälle zu Problemen.
Nullable-Beschränkungen
In objektorientierten Sprachen ist ein Feld oft standardmäßig nullable, es sei denn, es wird explizit initialisiert. In relationalen Datenbanken ist die NOT NULL-Beschränkung eine Leistungs- und Integritätsoptimierung. Eine Abweichung führt hier zu Laufzeitfehlern.
- Standardwerte: Eine Klasse könnte annehmen, dass ein String-Feld standardmäßig auf eine leere Zeichenkette festgelegt ist. Die Datenbank könnte es stattdessen auf NULL festlegen. Der Code, der eine leere Zeichenkette erwartet, stürzt ab, wenn er NULL erhält.
- Validierung: Die Validierung auf Anwendungsebene könnte zulassen, dass ein Feld NULL ist. Das Datenbankschema lehnt dies ab. Dies erzeugt einen Konflikt zwischen der Geschäftslogik und der Speicherebene.
Numerische Genauigkeit und Skalierung
Finanzdaten erfordern hohe Genauigkeit. Eine Klasse könnte eine BigDecimal oder Dezimal Typ zum Umgang mit Währungen. Die Datenbank muss einen entsprechenden Spaltentyp unterstützen, der eine definierte Genauigkeit und Skalierung hat.
- Ausschneiden: Wenn die Datenbankspalte als definiert ist
DECIMAL(10, 2)aber die Anwendungslogik versucht, zu speichernDECIMAL(10, 4), tritt Datenverlust stillschweigend oder über einen Fehler auf. - Float vs. Dezimal: Die Verwendung von Gleitkommawerten für Geldbeträge ist ein häufiger Anti-Pattern. Während eine Klasse möglicherweise
doubleaus Leistungsgründen verwendet, sollte die Datenbank exakte Arithmetik erzwingen, um Rundungsfehler in der Buchhaltung zu vermeiden.
🏷️ Namenskonventionen und Identität
Konsistenz bei der Namensgebung ist für die Wartbarkeit entscheidend. Allerdings unterscheiden sich die Konventionen, die in Programmiersprachen verwendet werden, oft von denen, die in Datenbankmanagementsystemen verwendet werden.
Snake_case vs. CamelCase
Java und C# verwenden typischerweise camelCase für Klassen-Eigenschaften und Feldnamen. Viele relationale Datenbanken bevorzugen snake_case für Tabellen- und Spaltennamen. Während Abbildungstools diese Umwandlung oft automatisch behandeln, könnte die manuelle Erstellung von Schemata diese Regel verletzen.
- Groß-/Kleinschreibung: Einige Datenbanken sind Groß-/Kleinschreibung sensitiv, andere nicht. Eine Spalte mit dem Namen
FirstNamein der Datenbank könnte als abgefragt werdenfirstnameim Code, was je nach Serverkonfiguration zu Fehlern führen kann. - Reservierte Wörter: Klassen-Eigenschaften könnten Namen verwenden, die als reservierte Schlüsselwörter in der Datenbanksprache gelten, wie zum Beispiel
OrderoderUser. Diese erfordern Anführungszeichen oder Aliase, was die Abfrageerzeugung komplizierter macht.
Primärschlüssel und Fremdschlüssel
Die Wahl der Primärschlüsselstrategie ist ein weiterer häufiger Konfliktpunkt. Klassen stützen sich oft auf natürliche Schlüssel (wie einen Benutzernamen oder eine E-Mail-Adresse) oder künstliche Schlüssel (wie eine automatisch generierte ID).
- Natürliche Schlüssel:Die Verwendung eines Geschäfts-Werts als Primärschlüssel kann das Schema starr machen. Wenn sich die Geschäftsregel ändert (z. B. eine E-Mail-Adresse), müssen die Fremdschlüssel-Verweise überall aktualisiert werden.
- Künstliche Schlüssel:Die Verwendung einer automatisch erhöhenden ID ist sicherer für Joins, führt aber zu einer zusätzlichen Spalte, die im Geschäftslogik-Kontext keine semantische Bedeutung hat.
⚡ Leistungsabwägungen
Die Gestaltung eines Schemas, das einem Klassendiagramm entspricht, ignoriert oft Leistungsaspekte. Theoretische Korrektheit entspricht nicht immer betrieblicher Effizienz.
Normalisierung vs. Denormalisierung
Klassendiagramme spiegeln oft normalisierte Datenstrukturen wider, um Redundanz zu vermeiden. Die Datenbankleistung profitiert jedoch manchmal von einer Denormalisierung, um die Anzahl der Joins bei Lesevorgängen zu reduzieren.
- Komplexität von Joins:Eine komplexe Klassenhierarchie erfordert möglicherweise mehrere Joins, um ein einzelnes Objekt abzurufen. In Systemen mit hohem Datenverkehr kann dies die Antwortzeiten erheblich verschlechtern.
- Caching:Denormalisierte Daten können leichter gecacht werden. Wenn das Schema zu stark normalisiert ist, muss die Anwendungsschicht komplexe Rekonstruktionslogik durchführen, was die Vorteile des Cachings aufhebt.
Indizierungsstrategien
Indizes werden auf Datenbankebene definiert, um Abfragen zu beschleunigen, sind aber selten in einem Klassendiagramm sichtbar. Das Fehlen von Indizes in der Schema-Designphase kann zu langsamen Abfragen führen.
- Fremdschlüssel-Indizes:Fremdschlüsselspalten sollten idealerweise indiziert werden, um Joins zu beschleunigen. Wenn das Schema diese Indizes weglässt, führen Abfragen nach verwandten Daten zu vollständigen Tabellen-Scans.
- Suchmuster: Wenn die Anwendung häufig nach einem bestimmten Attribut sucht, ist ein Datenbankindex erforderlich. Wenn das Klassendiagramm dieses Attribut hervorhebt, das Schema jedoch keinen Index dafür definiert, leidet die Leistung.
🔍 Erkennen und Beheben von Abweichungen
Die Identifizierung der Stellen, an denen das Schema vom Modell abweicht, ist der erste Schritt zur Lösung. Dieser Prozess erfordert eine Kombination aus automatisierten Tools und manueller Überprüfung.
Schema-Vergleichstools
Automatisierte Vergleichstools können Unterschiede zwischen dem erwarteten Zustand (abgeleitet aus dem Klassendiagramm oder dem Code) und dem tatsächlichen Zustand (der physischen Datenbank) hervorheben.
- Änderungserkennung: Diese Tools können fehlende Spalten, geänderte Datentypen oder entfernte Einschränkungen erkennen.
- Migrations-Skripte: Sie können das erforderliche SQL generieren, um das Schema mit dem Modell abzustimmen, wodurch manuelle Fehler reduziert werden.
Manuelle Überprüfung
Automatisierung ist hilfreich, aber menschliche Überprüfung ist bei komplexer Logik notwendig. Überprüfer sollten Folgendes prüfen:
- Sind alle Klassenfelder durch Datenbankspalten dargestellt?
- Stimmen die Datentypen genau überein, einschließlich Länge und Genauigkeit?
- Sind Beziehungen ordnungsgemäß mit Fremdschlüsseln eingeschränkt?
- Sind Namenskonventionen durchgehend konsistent?
Häufige Abbildungsszenarien und mögliche Probleme
| Abbildungsszenario | Darstellung im Klassendiagramm | Darstellung im Datenbankschema | Möglicher Fehler |
|---|---|---|---|
| Ein-zu-Eins | Einzelne Linie, die zwei Klassen verbindet | Fremdschlüssel in einer Tabelle (Eindeutigkeitsbeschränkung) | Fehlende Eindeutigkeitsbeschränkung erlaubt Doppelungen. |
| Ein-zu-Viele | Listensammlung in der übergeordneten Klasse | Fremdschlüssel in der Kindtabelle | Fehlender Index auf Fremdschlüssel verlangsamt Abfragen. |
| Viele-zu-Viele | Verknüpfungsklasse oder Assoziation | Verbindungstabelle mit zwei Fremdschlüsseln | Auslassung der Verbindungstabelle führt zu Datenverlust. |
| Vererbung | Extends-Schlüsselwort oder Pfeil | Einzelne Tabelle mit NULL-Werten ODER mehrere Tabellen | Lückenhaftigkeit in einzelner Tabelle oder komplexe Verknüpfungen bei mehreren. |
📝 Best Practices für die Ausrichtung
Um zukünftige Probleme zu minimieren, sollten Teams Strategien übernehmen, die die Ausrichtung zwischen logischem und physischem Modell priorisieren. Dies beinhaltet Kommunikation und Prozesse, nicht nur Technologie.
- Schema-erst-Ansatz: Definieren Sie das Datenbankschema, bevor Sie den Anwendungscode schreiben. Dadurch wird sichergestellt, dass die Speicher-Ebene die Beschränkungen vorgibt und der Code sich an sie anpassen muss.
- Code-erst-Ansatz: Definieren Sie zuerst die Klassen und generieren Sie dann das Schema. Dies ist für die Entwicklung schneller, birgt aber das Risiko, eine ineffiziente physische Struktur zu erzeugen, die später schwer zu optimieren ist.
- Dokumentation: Pflegen Sie ein lebendiges Dokument, das Klassenattribute mit Datenbankspalten verknüpft. Dies dient als einziges Quellensystem für Entwickler und Datenbankadministratoren.
- Überprüfungszyklen: Integrieren Sie Überprüfungen der Datenbankschemata in den Code-Review-Prozess. Kein Code sollte ohne Überprüfung, ob die Migrationsskripte den Klassenänderungen entsprechen, gemergt werden.
🛠️ Umgang mit veralteten Systemen
Nicht alle Projekte beginnen mit einer leeren Fläche. Viele Organisationen müssen sich mit veralteten Datenbanken auseinandersetzen, die nicht den aktuellen Klassendiagrammen entsprechen. Das Refactoring in diesem Kontext erfordert Vorsicht.
- Strangler-Fig-Muster: Bewegen Sie schrittweise neue Funktionalitäten in ein neues Schema, während das alte System weiterhin betriebsbereit bleibt. Dadurch kann das Klassendiagramm sich entwickeln, ohne bestehende Integrationen zu stören.
- Ansichten und Staging: Erstellen Sie Datenbankansichten, um die Daten in einem Format darzustellen, das dem neuen Klassendiagramm entspricht, ohne die zugrundeliegenden Tabellen sofort zu verändern.
- Schrittweise Migration: Bewegen Sie die Daten in Stapeln. Überprüfen Sie die Integrität nach jedem Stapel, bevor Sie zum nächsten übergehen. Dadurch wird das Risiko von Datenkorruption während des Übergangs minimiert.
🚀 Vorwärts schauen
Die Lücke zwischen dem Klassendiagramm und dem Datenbankschema ist eine inhärente Herausforderung der Softwareentwicklung. Sie entsteht aus den grundlegenden Unterschieden zwischen der Art, wie Computer Logik verarbeiten, und der Art, wie sie Informationen speichern. Es gibt keine perfekte Lösung, die diesen Reibungswiderstand vollständig beseitigt, aber es gibt Strategien, um ihn effektiv zu managen.
Durch das Verständnis der Feinheiten von Vererbung, Beziehungen, Datentypen und Namenskonventionen können Teams die Häufigkeit von Fehlern reduzieren. Regelmäßige Audits und der Einsatz automatisierter Werkzeuge helfen, die Synchronisation über die Zeit aufrechtzuerhalten. Das Ziel ist nicht, die Datenbank exakt wie den Code aussehen zu lassen, sondern sicherzustellen, dass die Zuordnung zwischen ihnen transparent, konsistent und leistungsstark ist. Wenn die physische Speicherung mit der logischen Gestaltung übereinstimmt, wird die Entwicklung vorhersehbarer, und das System bleibt unter Last stabil.