










En la arquitectura de software moderna, la desconexión entre el modelo orientado a objetos utilizado en el código de la aplicación y el modelo relacional utilizado en el almacenamiento persistente es un desafío constante. Los desarrolladores frecuentemente enfrentan situaciones en las que la representación visual de las estructuras de datos en un diagrama de clases diverge significativamente de la disposición física de las tablas y columnas en el esquema de la base de datos. Esta discrepancia no es meramente estética; representa una fricción arquitectónica fundamental que puede provocar problemas de integridad de datos, cuellos de botella de rendimiento y costos de mantenimiento aumentados. Comprender las causas raíz de estas desalineaciones es esencial para construir sistemas robustos y escalables.
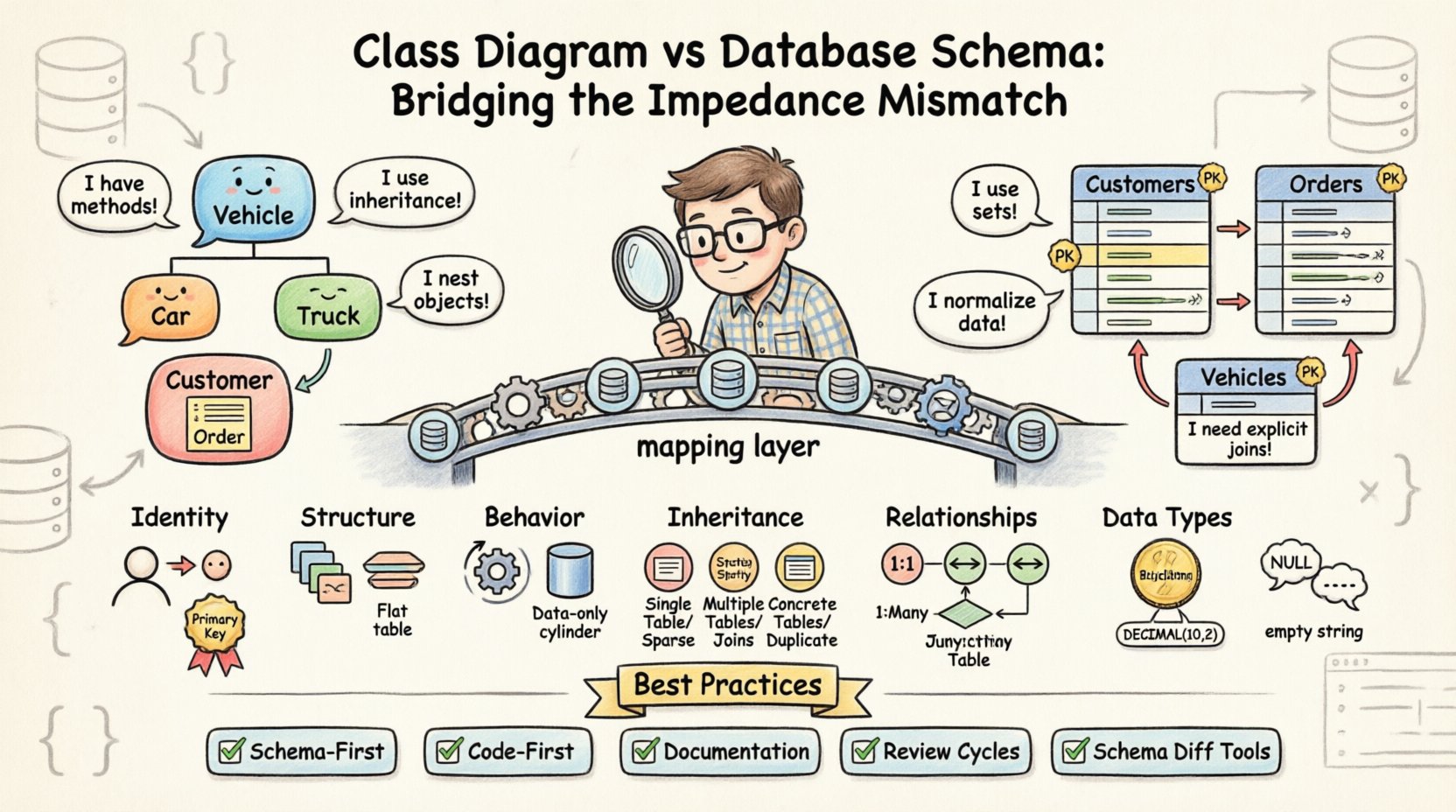
Cuando un diagrama de clases no coincide con el esquema de base de datos subyacente, se genera una desalineación de impedancia. Este término describe el conjunto de dificultades inherentes al uso de lenguajes de programación orientados a objetos para resolver problemas que existen en un entorno de base de datos relacional. Mientras que el mundo de los objetos opera con instancias, métodos e herencia, el mundo de las bases de datos se basa en conjuntos, filas y claves foráneas. Cerrar esta brecha requiere decisiones de diseño deliberadas y una validación rigurosa.
🔄 La tensión fundamental: Objetos frente a tablas
La diferencia fundamental radica en la filosofía del almacenamiento de datos. Las clases orientadas a objetos encapsulan estado y comportamiento juntos. En contraste, las bases de datos relacionales normalizan los datos para reducir la redundancia. Esta divergencia crea varias áreas específicas en las que los dos modelos tienen dificultades para sincronizarse.
- Identidad:Los objetos se identifican mediante una referencia de memoria o un identificador único de objeto durante la ejecución. Las bases de datos utilizan claves primarias, a menudo enteros autoincrementales o UUIDs, que existen independientemente del ciclo de vida de la aplicación.
- Estructura:Una clase puede tener objetos anidados complejos, colecciones y referencias circulares. Una tabla de base de datos no puede almacenar nativamente un objeto anidado sin aplanarlo o crear una tabla separada.
- Comportamiento:Las clases contienen métodos que manipulan datos. Las tablas de base de datos contienen solo datos; cualquier lógica debe manejarse mediante procedimientos almacenados o fuera de la capa de base de datos.
Cuando los desarrolladores intentan mapear estos dos paradigmas directamente sin una abstracción cuidadosa, ocurren errores. La capa de mapeo a menudo actúa como un traductor, pero ningún traductor es perfecto. Los matices en la lógica, el manejo de valores nulos y la conversión de tipos a menudo se pierden en la traducción.
🏗️ Discrepancias estructurales en el mapeo
Una de las fuentes más comunes de desalineación involucra cómo se manejan las relaciones entre entidades. En un diagrama de clases, las relaciones a menudo se representan como líneas simples que indican asociaciones. En un esquema de base de datos, estas asociaciones requieren restricciones de clave foránea explícitas y a menudo tablas de unión intermedias.
Jerarquías de herencia
Los sistemas orientados a objetos prosperan con la herencia. Una Vehículo clase podría tener subclases como Automóvil y Camión. Esto permite la polimorfía y la reutilización de código. Sin embargo, las bases de datos relacionales no admiten la herencia de forma nativa. Para modelar esto, los ingenieros deben elegir entre estrategias específicas, cada una con sus propias compensaciones.
- Tabla por jerarquía:Una sola tabla almacena todos los datos del padre y de todas las subclases. Esto es simple, pero conduce a columnas dispersas y valores nulos cuando se utilizan campos específicos de subclase.
- Tabla por subclase:Cada clase recibe su propia tabla. La tabla del padre almacena los atributos comunes, mientras que las tablas hijas almacenan los específicos, vinculados mediante una clave foránea. Esto aumenta la complejidad de las uniones necesarias para recuperar un objeto completo.
- Tabla por clase concreta:Cada clase concreta recibe una tabla completa que contiene todos los atributos. Esto evita las uniones, pero requiere duplicar los datos comunes en múltiples tablas.
Si el diagrama de clases muestra una jerarquía de herencia clara, pero el esquema de base de datos utiliza una sola tabla plana, el esquema no coincide con el modelo lógico. Esto puede provocar confusión durante el mantenimiento, ya que los desarrolladores podrían esperar columnas específicas que no existen debido a la estrategia de aplanamiento.
Asociación y agregación
Considere una Cliente clase con una colección de Pedido objetos. En el diagrama de clases, esta es una relación uno a muchos. En la base de datos, esto se representa mediante una columna de clave foránea en la Pedidos tabla que hace referencia a la Clientes tabla. Sin embargo, la dirección de la relación es a menudo donde ocurren los desajustes.
- Relaciones muchos a muchos: Un diagrama de clases podría mostrar
EstudianteyCursounidos por una asociación muchos a muchos. La base de datos requiere una tercera tabla, a menudo llamada tabla de unión o puente, para resolver esto. Si el esquema omite esta tabla, la relación no puede ser obligatoria. - Cardinalidad: Un diagrama de clases podría indicar una relación opcional (0..*). El esquema de la base de datos debe reflejar esto con claves foráneas nulas. Si el esquema impone una restricción NOT NULL, contradice la definición de la clase.
- Eliminaciones en cascada: En el código, eliminar un objeto padre podría eliminar automáticamente a los hijos. En la base de datos, esto requiere reglas de eliminación en cascada. Si estas no están configuradas, quedan registros huérfanos, rompiendo la integridad de los datos.
🛡️ Integridad de datos y desajustes de tipo
Más allá de la estructura, los tipos de datos reales definidos en la clase a menudo no coinciden con los tipos de columna de la base de datos. Aunque los sistemas modernos ofrecen amplias capacidades de mapeo, los casos extremos frecuentemente causan problemas.
Restricciones de nulabilidad
En los lenguajes orientados a objetos, un campo suele ser nulo por defecto a menos que se inicialice explícitamente. En las bases de datos relacionales, la restricción NOT NULL es una optimización de rendimiento e integridad. Una discrepancia aquí conduce a excepciones en tiempo de ejecución.
- Valores por defecto: Una clase podría asumir que un campo de cadena tiene como valor por defecto una cadena vacía. La base de datos podría establecerlo como NULL. El código que espera una cadena vacía fallará si recibe NULL.
- Validación: La validación a nivel de aplicación podría permitir que un campo sea nulo. El esquema de la base de datos lo rechaza. Esto crea un conflicto entre la lógica de negocio y la capa de almacenamiento.
Precisión y escala numéricas
Los datos financieros requieren alta precisión. Una clase podría usar un BigDecimal o Decimal tipo para manejar el dinero. La base de datos debe admitir un tipo de columna correspondiente con precisión y escala definidas.
- Truncamiento: Si la columna de la base de datos está definida como
DECIMAL(10, 2)pero la lógica de la aplicación intenta almacenarDECIMAL(10, 4), se produce pérdida de datos silenciosamente o mediante un error. - Float frente a Decimal: Usar tipos de punto flotante para el dinero es un patrón común. Aunque una clase podría usar
doublepara rendimiento, la base de datos debe forzar aritmética exacta para evitar errores de redondeo en contabilidad.
🏷️ Convenciones de nomenclatura e identidad
La consistencia en la nomenclatura es vital para la mantenibilidad. Sin embargo, las convenciones utilizadas en los lenguajes de programación a menudo difieren de las utilizadas en los sistemas de gestión de bases de datos.
Snake_case frente a CamelCase
Java y C# suelen usar camelCase para propiedades de clases y nombres de campos. Muchas bases de datos relacionales prefieren snake_case para nombres de tablas y columnas. Aunque las herramientas de mapeo suelen manejar esta conversión automáticamente, la creación manual de esquemas podría violar esta regla.
- Sensibilidad a mayúsculas y minúsculas: Algunas bases de datos son sensibles a mayúsculas y minúsculas, mientras que otras no lo son. Una columna llamada
FirstNameen la base de datos podría consultarse comofirstnameen el código, lo que puede provocar errores dependiendo de la configuración del servidor. - Palabras reservadas: Las propiedades de clase podrían usar nombres que son palabras clave reservadas en el lenguaje de la base de datos, como
OrderoUser. Estas requieren comillas o alias, lo que complica la generación de consultas.
Claves primarias y claves foráneas
La elección de la estrategia de clave primaria es otro punto de fricción común. Las clases a menudo dependen de claves naturales (como un nombre de usuario o correo electrónico) o claves de sustitución (como un ID generado automáticamente).
- Claves naturales:Utilizar un valor del negocio como clave primaria puede hacer que el esquema sea rígido. Si cambia la regla de negocio (por ejemplo, un correo electrónico cambia), las referencias de clave foránea deben actualizarse en todas partes.
- Claves de sustitución:Utilizar un ID autoincremental es más seguro para las uniones, pero introduce una columna adicional que no tiene significado semántico en la lógica de negocio.
⚡ Compromisos de rendimiento
Diseñar un esquema que coincida con un diagrama de clases a menudo ignora las implicaciones de rendimiento. La corrección teórica no siempre equivale a eficiencia operativa.
Normalización frente a denormalización
Los diagramas de clases a menudo reflejan estructuras de datos normalizadas para evitar redundancias. Sin embargo, el rendimiento de la base de datos a veces se beneficia de la denormalización para reducir el número de uniones necesarias durante las operaciones de lectura.
- Complejidad de unión:Una jerarquía de clases compleja podría requerir múltiples uniones para recuperar un solo objeto. En sistemas de alto tráfico, esto puede degradar significativamente los tiempos de respuesta.
- Caché:Los datos denormalizados se pueden cachear más fácilmente. Si el esquema está demasiado normalizado, la capa de aplicación debe realizar lógica de reconstrucción compleja, anulando los beneficios de la caché.
Estrategias de indexación
Los índices se definen a nivel de base de datos para acelerar las consultas, pero rara vez son visibles en un diagrama de clases. La ausencia de definiciones de índices en el diseño del esquema puede provocar consultas lentas.
- Índices de clave foránea:Las columnas de clave foránea deberían indexarse idealmente para acelerar las operaciones de unión. Si el esquema omite estos índices, las búsquedas en datos relacionados escanearán tablas enteras.
- Patrones de búsqueda:Si la aplicación busca con frecuencia por un atributo específico, se requiere un índice de base de datos. Si el diagrama de clases destaca este atributo pero el esquema no lo indexa, el rendimiento sufrirá.
🔍 Detección y resolución de desajustes
Identificar dónde el esquema diverge del modelo es el primer paso hacia la resolución. Este proceso requiere una combinación de herramientas automatizadas y auditoría manual.
Herramientas de diferencias de esquema
Las utilidades de comparación automatizadas pueden destacar las diferencias entre el estado esperado (derivado del diagrama de clases o del código) y el estado real (la base de datos física).
- Detección de cambios:Estas herramientas pueden identificar columnas faltantes, tipos de datos modificados o restricciones eliminadas.
- Scripts de migración:Pueden generar el SQL necesario para alinear el esquema con el modelo, reduciendo los errores manuales.
Auditoría manual
La automatización es útil, pero se necesita una revisión humana para lógica compleja. Los revisores deben verificar lo siguiente:
- ¿Todas las propiedades de la clase están representadas por columnas de la base de datos?
- ¿Coinciden los tipos de datos exactamente, incluida la longitud y la precisión?
- ¿Las relaciones están correctamente restringidas con claves foráneas?
- ¿Las convenciones de nomenclatura son coherentes en todo momento?
Escenarios comunes de mapeo y posibles problemas
| Escenario de mapeo | Representación del diagrama de clases | Representación del esquema de la base de datos | Posible problema |
|---|---|---|---|
| Uno a uno | Línea simple que conecta dos clases | Clave foránea en una tabla (restricción única) | La ausencia de una restricción única permite duplicados. |
| Uno a muchos | Colección de lista en la clase padre | Clave foránea en la tabla hija | La ausencia de un índice en la clave foránea ralentiza las consultas. |
| Muchos a muchos | Clase de enlace o asociación | Tabla de unión con dos claves foráneas | La omisión de la tabla de unión causa pérdida de datos. |
| Herencia | Palabra clave extends o flecha | Tabla única con valores nulos O múltiples tablas | Escasez en una sola tabla o combinaciones complejas en múltiples. |
📝 Mejores prácticas para la alineación
Para minimizar el fricción futura, los equipos deben adoptar estrategias que prioricen la alineación entre los modelos lógico y físico. Esto implica comunicación y procesos, no solo tecnología.
- Enfoque primero el esquema: Defina el esquema de la base de datos antes de escribir el código de la aplicación. Esto garantiza que la capa de almacenamiento determine las restricciones, y el código debe adaptarse a ellas.
- Enfoque primero el código: Defina las clases primero, luego genere el esquema. Esto es más rápido para el desarrollo, pero conlleva el riesgo de crear una estructura física ineficiente que será difícil de optimizar después.
- Documentación:Mantenga un documento vivo que asocie las propiedades de las clases con las columnas de la base de datos. Esto sirve como la única fuente de verdad para los desarrolladores y administradores de bases de datos.
- Ciclos de revisión:Incluya revisiones del esquema de la base de datos en el proceso de revisión de código. Ningún código debe fusionarse sin verificar que los scripts de migración coincidan con los cambios en las clases.
🛠️ Manejo de sistemas heredados
No todos los proyectos comienzan con una hoja en blanco. Muchas organizaciones deben lidiar con bases de datos heredadas que no coinciden con los diagramas de clases actuales. Refactorizar en este contexto requiere precaución.
- Patrón Figuera Estranguladora:Mueva gradualmente la nueva funcionalidad a un nuevo esquema mientras el sistema antiguo permanece operativo. Esto permite que el diagrama de clases evolucione sin romper las integraciones existentes.
- Vistas y preparación:Cree vistas de base de datos para presentar los datos en un formato que coincida con el nuevo diagrama de clases sin modificar inmediatamente las tablas subyacentes.
- Migración incremental:Mueva los datos por lotes. Verifique la integridad después de cada lote antes de proceder al siguiente. Esto minimiza el riesgo de corrupción de datos durante la transición.
🚀 Avanzando
La brecha entre el diagrama de clases y el esquema de la base de datos es un desafío inherente en la ingeniería de software. Surge de las diferencias fundamentales entre cómo los ordenadores procesan la lógica y cómo almacenan la información. No existe una solución perfecta que elimine completamente este fricción, pero existen estrategias para gestionarla de forma efectiva.
Al comprender las sutilezas de la herencia, las relaciones, los tipos de datos y las convenciones de nomenclatura, los equipos pueden reducir la frecuencia de errores. La auditoría regular y el uso de herramientas automatizadas ayudan a mantener la sincronización con el tiempo. El objetivo no es hacer que la base de datos se vea exactamente como el código, sino asegurar que el mapeo entre ambos sea transparente, consistente y eficiente. Cuando el almacenamiento físico se alinea con el diseño lógico, el desarrollo se vuelve más predecible y el sistema permanece estable bajo carga.