











Dans le monde rapide du développement logiciel, l’écart entre une idée et une fonctionnalité déployée détermine souvent le succès. Ce parcours commence par un simple concept, souvent capté sous la forme d’une “histoire utilisateur, et parcourt les phases d’analyse, de conception, d’implémentation, de test et de déploiement. Comprendre le cycle de vie complet de cycle de vie de l’histoire utilisateur est essentiel pour les équipes d’ingénierie visant l’efficacité et la qualité.
Les méthodologies agiles ont déplacé l’accent de la documentation rigide vers la livraison itérative de valeur. Toutefois, sans un processus structuré, même les meilleures idées peuvent se perdre dans la traduction. Ce guide décrit le flux complet d’une histoire utilisateur, garantissant une clarté à chaque étape, de l’étincelle initiale d’un besoin jusqu’à la dernière ligne de code.
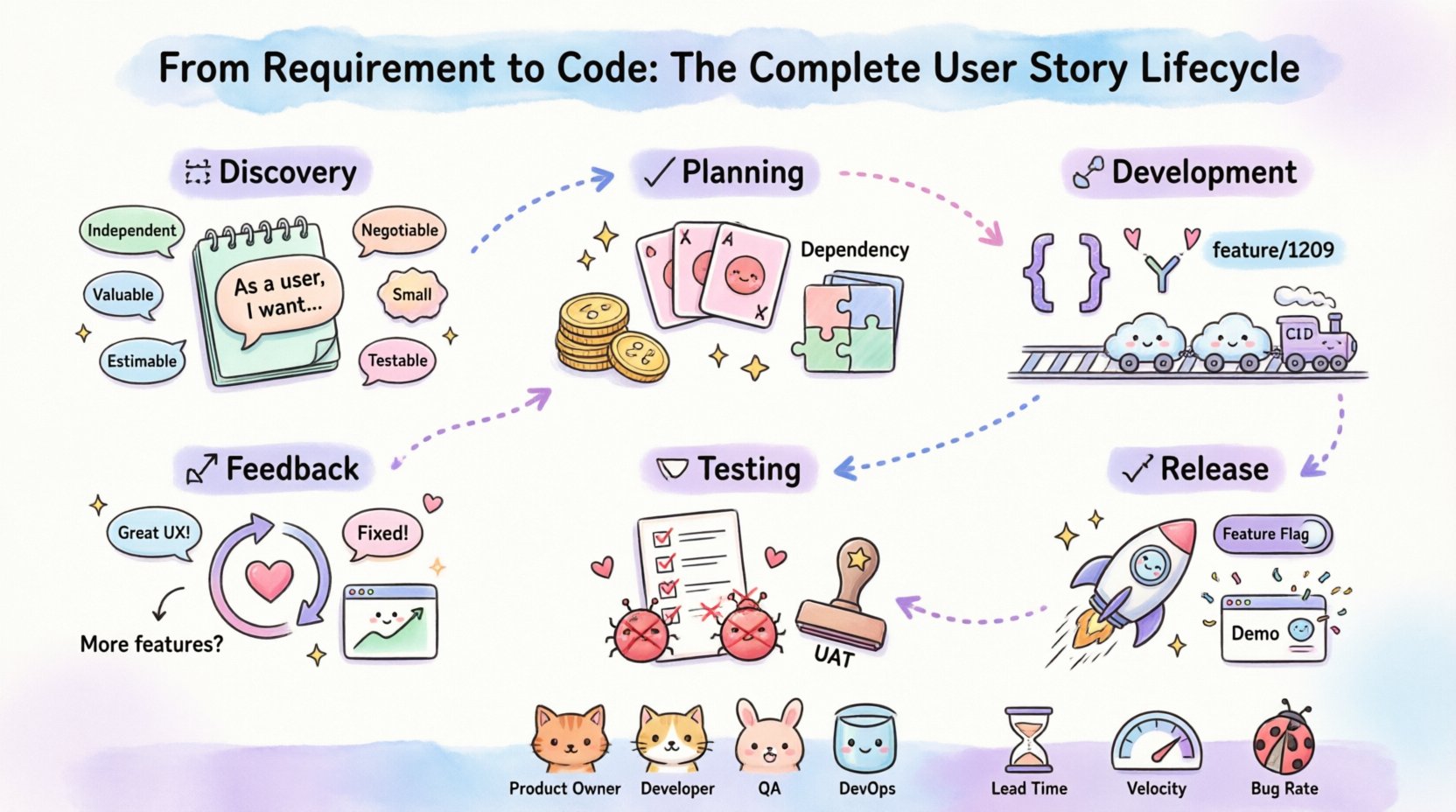
Comprendre l’histoire utilisateur 📝
Une histoire utilisateur est une description courte et simple d’une fonctionnalité, formulée du point de vue de la personne qui souhaite cette nouvelle capacité. Ce n’est pas simplement une tâche ; c’est une promesse de valeur. Le format standard suit généralement la structure : « En tant qu'[type d’utilisateur], je veux [un objectif] afin que [une raison]. »
Pour qu’un cycle de vie fonctionne efficacement, l’histoire doit être viable. Elle doit passer les critères INVEST :
- Indépendant :Les histoires ne doivent pas dépendre d’autres pour être développées.
- Négociable :Les détails sont discutés, et non figés dès le départ.
- Valeur :Elle doit apporter de la valeur à l’utilisateur final ou au donneur d’ordre.
- Estimable :L’équipe doit pouvoir estimer l’effort nécessaire.
- Petit :Elle doit tenir dans une seule itération ou sprint.
- Testable :Il doit exister des critères clairs pour vérifier sa complétion.
Lorsque ces conditions sont remplies, l’histoire est prête à entrer dans le flux de travail actif.
Phase 1 : Découverte et affinement 🧩
Avant toute écriture de code, l’histoire doit être comprise. Cette phase est souvent appelée affinement du backlogou affinement. C’est là que l’ambiguïté est réduite.
1.1 Capture initiale
Les exigences commencent souvent par des notes sommaires, des messages vocaux ou des comptes rendus de réunion. L’objectif ici est de transformer ces éléments en un brouillon d’histoire. Le propriétaire du produit ou le partie prenante définit le problème central.
- Qui est l’utilisateur principal ?
- Quelle est l’action spécifique ?
- Pourquoi cela est-il nécessaire maintenant ?
1.2 Viabilité technique
Les développeurs examinent le brouillon pour identifier les contraintes techniques. Il ne s’agit pas de dire « non », mais de comprendre la complexité dès le départ. Des questions concernant le schéma de base de données, les limites de l’API ou l’intégration avec des systèmes hérités sont soulevées ici.
1.3 Définition des critères d’acceptation
C’est la partie la plus critique du cycle de vie. Les critères d’acceptation définissent les limites de l’histoire. Ce sont les conditions qui doivent être remplies pour que l’histoire soit considérée comme terminée.
Utiliser un tableau pour structurer ces critères aide à la fois les développeurs et les testeurs :
| Catégorie | Critères d’exemple | Priorité |
|---|---|---|
| Fonctionnel | L’utilisateur peut réinitialiser son mot de passe via un lien par courriel | À avoir obligatoirement |
| Performance | La page se charge en moins de 2 secondes | À avoir si possible |
| Sécurité | Les mots de passe sont hachés avant stockage | À avoir obligatoirement |
| Utilisabilité | Un message d’erreur s’affiche si l’entrée est invalide | Pourrait avoir |
Des critères clairs évitent le piège courant du « Je pensais que ça fonctionnait comme ça ». Ils servent de contrat entre l’équipe métier et l’équipe technique.
Phase 2 : Planification et estimation 📊
Une fois l’histoire affinée, elle passe à la phase de planification. L’équipe décide quand le travail sera effectué en fonction de sa capacité et de sa priorité.
2.1 Estimation par points d’histoire
Plutôt que d’estimer le temps (en heures), les équipes utilisent souventpoints d’histoire. Cela tient compte de la complexité, de l’effort et du risque. Des techniques comme le Poker d’Planning sont utilisées pour atteindre un consensus sans biais.
- Faible complexité :Modifications simples, risque minimal.
- Complexité moyenne :Nouvelles fonctionnalités, certaines intégrations.
- Haute complexité :Modifications d’architecture, migration de données importante.
2.2 Cartographie des dépendances
Aucune histoire n’existe en vase clos. Si l’histoire B nécessite des données de l’histoire A, cette dépendance doit être notée. Les dépendances peuvent bloquer l’avancement, identifier donc tôt permet une meilleure planification.
2.3 Engagement du sprint
L’équipe sélectionne les histoires qui correspondent à sa vitesse. Ce n’est pas une obligation de la direction, mais un engagement des développeurs fondé sur leur compréhension du travail.
Phase 3 : Développement et mise en œuvre 🛠️
C’est la phase centrale où les exigences se transforment en logiciel. Elle implique la conception, la programmation et les tests unitaires.
3.1 Conception et architecture
Avant d’écrire la logique, le design de la solution est esquissé. Cela peut inclure des diagrammes de flux, des schémas de base de données ou des maquettes d’interface utilisateur. L’objectif est de s’assurer que l’approche technique correspond aux critères d’acceptation.
3.2 Normes de codage
La cohérence est essentielle. Le code doit respecter les guides de style établis. La lisibilité prime sur la concision. Les commentaires doivent expliquer pourquoiquelque chose est fait, et non pas quoi est en cours de réalisation.
3.3 Stratégie de gestion de version
Chaque histoire devrait idéalement avoir sa propre branche. Cela isole les modifications et permet une fusion en toute sécurité. La convention de nommage des branches doit refléter l’ID de l’histoire pour un suivi facile.
feature/1024-connexion-utilisateurfix/1025-reinitialisation-mot-de-passerefactor/1026-reponse-api
3.4 Intégration continue
Le code est fusionné fréquemment pour éviter le « enfer d’intégration ». Les builds automatisés vérifient que le nouveau code ne rompt pas immédiatement la fonctionnalité existante.
Phase 4 : Vérification et test 🧪
Une histoire n’est pas terminée tant qu’elle n’a pas été vérifiée. Cette phase assure que le produit répond aux critères d’acceptation définis à la phase 1.
4.1 Tests unitaires
Les développeurs écrivent des tests pour les composants individuels. Cela garantit que la logique résiste à diverses entrées. Une forte couverture du code renforce la confiance dans la stabilité du code.
4.2 Tests d’intégration
Comment cette histoire interagit-elle avec les autres parties du système ? La nouvelle borne d’API communique-t-elle correctement avec l’interface frontale ? Le nouveau flux de paiement déclenche-t-il le bon courriel ?
4.3 Tests d’acceptation utilisateur (UAT)
Souvent, le propriétaire du produit ou un testeur désigné vérifie l’histoire par rapport aux critères d’acceptation. Il s’agit du contrôle « Définition de terminé ». Si l’histoire réussit, elle est prête pour le déploiement.
4.4 Revue de code
Avant de fusionner dans la branche principale, un autre développeur examine les modifications. C’est une opportunité d’échange de connaissances et une barrière de qualité. Elle permet de détecter les erreurs logiques, les vulnérabilités de sécurité et les violations de style.
- Vérifier la logique : Le code résout-il le problème ?
- Vérifier la sécurité : Les entrées sont-elles nettoyées ?
- Vérifier la lisibilité : Quelqu’un d’autre peut-il le maintenir ?
Phase 5 : Revue et déploiement 🚦
Une fois les tests terminés, l’histoire est préparée pour l’utilisateur.
5.1 Déploiement
Le déploiement peut être automatisé via des pipelines CI/CD. L’objectif est de déplacer le code d’un environnement de développement vers la production avec une intervention manuelle minimale. Cela réduit le risque d’erreur humaine lors du processus de publication.
5.2 Drapeaux de fonctionnalité
Pour les grandes versions, les drapeaux de fonctionnalité permettent de déployer le code mais de le désactiver. Cela constitue une sécurité. Si un problème survient, la fonctionnalité peut être désactivée sans revenir en arrière sur tout le déploiement.
5.3 La démonstration
Les parties prenantes sont présentées au logiciel fonctionnel. Ce n’est pas seulement une formalité ; c’est le moment de vérité. Les retours sont recueillis immédiatement. Si l’implémentation s’écarte des attentes, des ajustements sont apportés.
Phase 6 : Maintenance et retour d’information 🔄
Le cycle de vie ne s’arrête pas à la publication. Il revient en boucle vers la découverte.
6.1 Surveillance
Les journaux et les métriques suivent la performance de la fonctionnalité en production. Les utilisateurs utilisent-ils cette fonctionnalité ? Y a-t-il des erreurs dans les journaux ? La performance atteint-elle les objectifs fixés à la phase 1 ?
6.2 Boucle de retour
Les retours des utilisateurs guident les itérations futures. Un rapport de bogues ou une demande de fonctionnalité peut donner naissance à une nouvelle histoire utilisateur. Cela clôt la boucle, garantissant que le produit évolue selon les besoins des utilisateurs.
Péchés courants dans le cycle de vie 🐛
Même les équipes expérimentées rencontrent des défis. Reconnaître ces problèmes courants aide à éviter les retards.
- Débordement de portée :Ajouter des exigences au milieu du sprint sans ajuster le calendrier.
- Critères flous :Des critères d’acceptation ambigus entraînent des reprises de travail.
- Ignorer les tests :Sauter les tests pour gagner du temps entraîne des bogues plus tard.
- Communication en silos :Développeurs et testeurs travaillant en isolement.
- Sur-estimation :Surévaluer les estimations pour être en sécurité, ce qui fausse le suivi de la vitesse.
Rôles et responsabilités 👥
Une clarté sur qui fait quoi évite les frictions. Un résumé simplifié des rôles :
| Rôle | Responsabilité principale | Résultat clé |
|---|---|---|
| Product Owner | Définit la valeur et priorise | Backlog affiné |
| Développeur | Construit et met en œuvre | Code fonctionnel |
| Ingénieur QA | Vérifie la qualité et les critères | Rapports de test |
| DevOps | Gère l’infrastructure et le déploiement | Environnement stable |
Indicateurs de mesure 📈
Pour améliorer le cycle de vie, les équipes doivent mesurer leurs performances. Évitez les indicateurs trompeurs et concentrez-vous sur le flux.
- Délai de livraison : Temps écoulé entre la demande et la production.
- Temps de cycle : Temps passé à travailler activement sur l’histoire.
- Vitesse : La quantité de travail accomplie par sprint.
- Taux de bogues : Nombre de défauts détectés après le lancement.
Suivre ces indicateurs aide à identifier les goulets d’étranglement. Si le délai de livraison augmente, le processus doit être revu. Si le taux de bogues augmente, la rigueur du test pourrait nécessiter une amélioration.
Meilleures pratiques pour réussir 🎯
Mettre en œuvre ces habitudes assure un cycle de vie plus fluide.
1. Collaborez tôt
Impliquez les testeurs et les architectes pendant la phase de révision. Détecter les problèmes tôt permet d’économiser beaucoup de temps plus tard.
2. Gardez les histoires courtes
Une histoire qui prend deux semaines à construire est trop grande. Décomposez-la. Des histoires plus courtes offrent un retour plus rapide et un risque moindre.
3. Automatisez autant que possible
Le test, le déploiement et la surveillance automatisés réduisent le travail manuel. Cela permet à l’équipe de se concentrer sur la création de valeur plutôt que sur des tâches répétitives.
4. Communiquez en continu
Les mises à jour de statut doivent être transparentes. Si une histoire est bloquée, communiquez-le immédiatement. Le silence entraîne souvent des surprises.
5. Respectez la définition de « terminé »
Une histoire n’est pas « presque terminée ». Elle est soit terminée, soit non. Compromettre la définition de « terminé » accumule une dette technique qui ralentit l’équipe au fil du temps.
Dernières réflexions sur le flux de travail 🏗️
Le parcours depuis la demande jusqu’au code est complexe. Il exige une coordination, une discipline et une communication claire. En respectant un cycle de vie structuré, les équipes peuvent livrer un logiciel fiable, pertinent et aligné sur les besoins des utilisateurs.
Chaque étape de ce processus contribue à la qualité du produit final. Négliger la révision entraîne de la confusion. Sauter les tests conduit à l’instabilité. Ignorer les retours conduit à l’obsolescence.
Optimiser ce flux de travail est un effort continu. Les équipes doivent régulièrement réfléchir à leur processus et s’adapter. L’objectif n’est pas seulement de livrer du code, mais de fournir des solutions qui résolvent efficacement des problèmes réels.
Avec un cycle de vie clair en place, le chemin de l’idée à la mise en œuvre devient prévisible. Cette prévisibilité renforce la confiance des parties prenantes et permet à l’équipe de développement de se concentrer sur ce qu’elle fait de mieux : construire de bons logiciels.