











सॉफ्टवेयर सिस्टम समय के साथ जटिल होते जाते हैं। एक सरल स्क्रिप्ट के रूप में शुरू होने वाला एक प्रोग्राम बाद में एक बातचीत करने वाले घटकों के नेटवर्क में बदल जाता है। स्पष्ट नक्शे के बिना, डेवलपर्स को अक्सर निर्भरताओं के जटिल जंगल में घूमना पड़ता है, जहां एक बग का मूल कारण या डेटा का अंतिम गंतव्य स्पष्ट नहीं होता है। इसी जगह विज़ुअल मॉडलिंग अत्यंत महत्वपूर्ण हो जाती है। विशेष रूप से, क्लास डायग्राम ऑब्जेक्ट-ओरिएंटेड एप्लिकेशन के लिए आर्किटेक्ट्योरल ब्लूप्रिंट के रूप में कार्य करता है। यह केवल क्लासेस की सूची देने से अधिक करता है; यह दिखाता है कि डेटा प्रणाली के भीतर कैसे आगे बढ़ता है, परिवर्तित होता है और संरक्षित रहता है।
एप्लिकेशन की मूल संरचना को समझने के लिए कोड के बाहर देखने की आवश्यकता होती है। इसके लिए एक ऐसी प्रतिनिधित्व की आवश्यकता होती है जो सिंटैक्स को छोड़ देती है और तर्क, संबंध और प्रवाह पर ध्यान केंद्रित करती है। क्लास डायग्राम के निर्माण को समझने से टीमें बॉटलनेक्स की भविष्यवाणी कर सकती हैं, जिम्मेदारियों को स्पष्ट कर सकती हैं और यह सुनिश्चित कर सकती हैं कि डेटा की अखंडता यूजर इंटरफेस से लेकर डेटाबेस तक बनी रहे। यह गाइड विज़ुअल डिज़ाइन के माध्यम से एप्लिकेशन संरचना को मैप करने के तकनीकी पहलुओं का अध्ययन करता है।
🧱 क्लास डायग्रामों का आधार
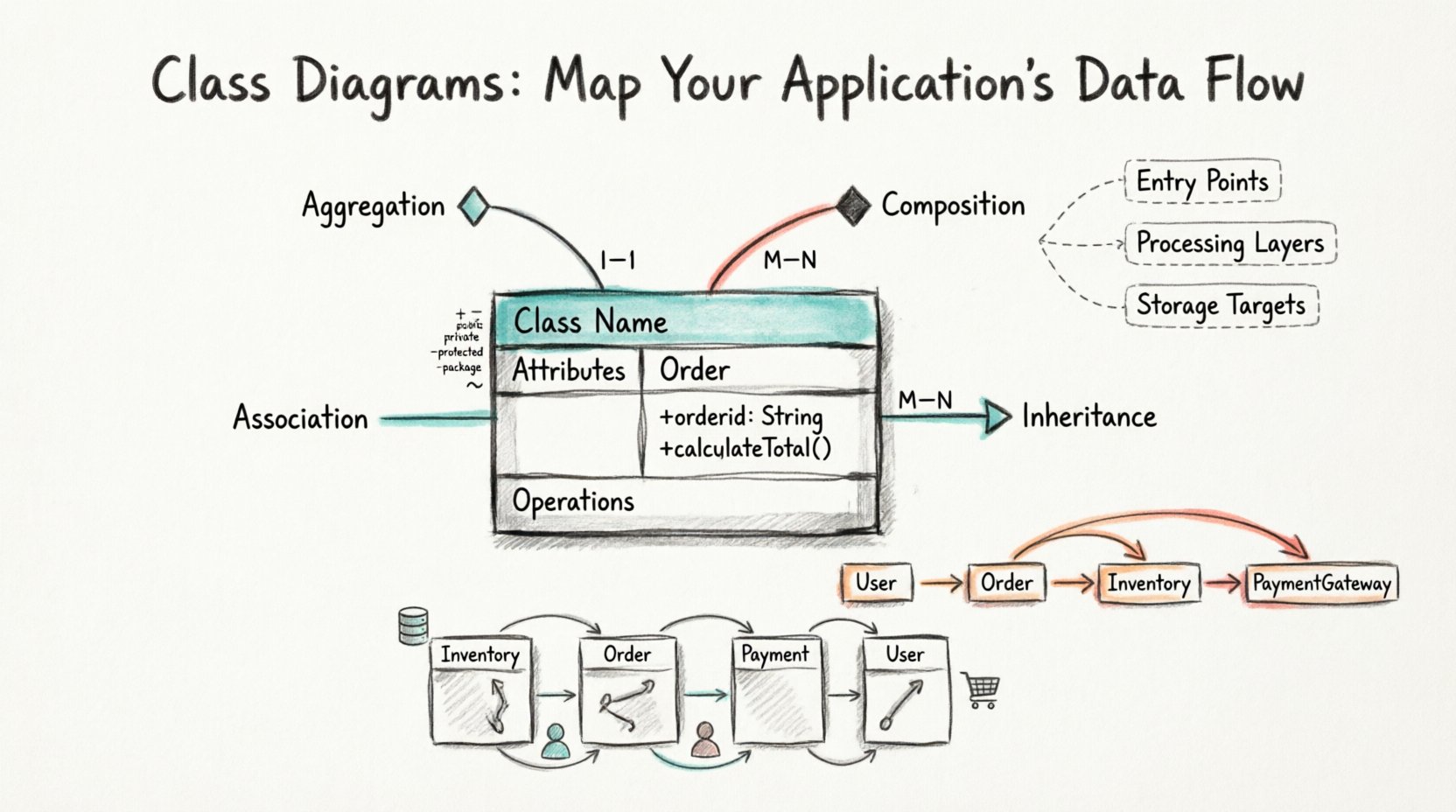
एक क्लास डायग्राम यूनिफाइड मॉडलिंग लैंग्वेज (UML) में एक स्थिर संरचना डायग्राम है। यह प्रणाली के क्लासेस, उनके लक्षण, संचालन (या विधियाँ), और वस्तुओं के बीच संबंधों को दिखाकर प्रणाली की संरचना का वर्णन करता है। अन्य अनुक्रम डायग्राम के विपरीत जो समय के साथ गतिशील व्यवहार को दर्ज करता है, एक क्लास डायग्राम एक विशिष्ट क्षण पर प्रणाली के डिज़ाइन की एक तस्वीर प्रदान करता है।
इस स्नैपशॉट की क्या कीमत है? यह डिज़ाइन और कार्यान्वयन के बीच एक अनुबंध के रूप में कार्य करता है। जब एक डेवलपर कोड लिखता है, तो वह वास्तव में डायग्राम में किए गए वादों को पूरा कर रहा होता है। यदि डायग्राम में दो क्लासेस के बीच एक विशिष्ट संबंध दिखाया गया है, तो कोड में उस संबंध को दर्शाना आवश्यक है। इस संरेखण से तकनीकी देनदारी कम होती है और प्रणाली के ढीले-ढाले फाइलों के संग्रह में बदलने से बचा जा सकता है।
🏗️ क्लास का अनातॉमी
डेटा फ्लो को प्रभावी ढंग से दृश्यमान बनाने के लिए, पहले क्लास के बनावट वाले घटकों को समझना आवश्यक है। एक मानक क्लास डायग्राम बॉक्स आमतौर पर तीन भागों में विभाजित होता है:
- क्लास नाम: शीर्ष पर स्थित, यह आमतौर पर प्रणाली के भीतर एक वस्तु का प्रतिनिधित्व करने वाला संज्ञा होता है। इसे बड़े अक्षरों में लिखा जाना चाहिए (उदाहरण के लिए,
ग्राहकयाआर्डर प्रोसेसर). - लक्षण: मध्य भाग में क्लास द्वारा धारण किए गए डेटा की सूची होती है। ये गुण या स्थिति चर होते हैं। उदाहरण के लिए
ईमेल पता,बैलेंस, यास्थिति. - संचालन: निचले भाग में क्लास द्वारा किए जा सकने वाले विधियों या कार्यों का विवरण होता है। ये क्रियाएँ होती हैं। उदाहरण के लिए
कैलकुलेट_टोटल(),सेंड_नोटिफिकेशन(), याअपडेट_प्रोफाइल().
प्रत्येक विशेषता और संचालन को एक दृश्यता संशोधक निर्धारित किया जाता है जो इसके प्रणाली के अन्य भागों के साथ कैसे बातचीत करता है, इसका निर्धारण करता है। डेटा प्रवाह का अनुसरण करने के लिए इन संशोधकों को समझना महत्वपूर्ण है।
| संशोधक | प्रतीक | पहुंच स्तर | डेटा प्रवाह के लिए अर्थ |
|---|---|---|---|
| सार्वजनिक | + |
सभी द्वारा प्राप्त किया जा सकता है | किसी भी अन्य क्लास द्वारा डेटा को पढ़ा या संशोधित किया जा सकता है। खुले मार्ग बनाता है। |
| निजी | - |
केवल क्लास के भीतर प्राप्त किया जा सकता है | डेटा एन्कैप्सुलेटेड है। प्रवाह केवल सार्वजनिक विधियों के माध्यम से होना चाहिए। |
| संरक्षित | # |
उपवर्गों द्वारा प्राप्त किया जा सकता है | डेटा विरासत पदानुक्रम के भीतर प्रवाहित होता है लेकिन बाहरी क्लासों से छिपा रहता है। |
| पैकेज | ~ |
पैकेज के भीतर प्राप्त किया जा सकता है | डेटा संबंधित मॉड्यूलों के बीच स्वतंत्र रूप से प्रवाहित होता है लेकिन अन्यत्र सीमित होता है। |
🔗 संबंधों और संबंधों को परिभाषित करना
क्लासेस कभी भी अकेले नहीं होती हैं। वे बातचीत के जाल में मौजूद होती हैं। क्लास बॉक्सों को जोड़ने वाली रेखाएं संबंधों का प्रतिनिधित्व करती हैं। ये संबंध डेटा के पारगमन और निर्भरता के गठन के तरीके को परिभाषित करते हैं। एक संबंध को गलत समझने से तनावपूर्ण जुड़ाव की स्थिति बन सकती है, जहां एक क्लास के बदलने से दूसरी क्लास टूट जाती है।
दृश्य करने के लिए चार मुख्य प्रकार के संबंध हैं:
- संबंध: दो क्लासों के बीच एक सरल लिंक जो इंगित करता है कि वे एक दूसरे के बारे में जानते हैं। यह संदर्भों के द्विदिशात्मक या एकदिशात्मक प्रवाह का प्रतिनिधित्व करता है। उदाहरण के लिए, एक
प्रबंधकप्रबंधित करता हैकर्मचारी. - एग्रीगेशन: एक विशिष्ट प्रकार का संबंध जो एक “पूर्ण-भाग” संबंध का प्रतिनिधित्व करता है जहां भाग पूर्ण के बिना स्वतंत्र रूप से अस्तित्व में हो सकता है। यदि
टीमके विघटन के बाद,खिलाड़ीवस्तुएं अभी भी अस्तित्व में हैं। - संघटन: एक मजबूत रूप है जहां भाग पूर्ण के बिना अस्तित्व में नहीं हो सकता है। यदि
घरको हटा दिया जाता है, तोकमरावस्तुएं अस्तित्व से बाहर हो जाती हैं। इसका तात्पर्य है कि जीवनचक्र में सख्त निर्भरता है। - विरासत (सामान्यीकरण): एक “है-एक” संबंध का प्रतिनिधित्व करता है। एक
वाहनमाता-पिता हैकारऔरट्रक। डेटा बच्चे से माता-पिता की ओर बहता है, जिसमें विशेषताएं और विधियां विरासत में मिलती हैं।
📈 डेटा प्रवाह गतिशीलता का दृश्यीकरण
जबकि एक क्लास आरेख स्थिर है, यह गतिशील व्यवहार को संकेत करता है। क्लास के बीच रेखाओं का अनुसरण करके आप डेटा के संभावित मार्गों को नक्शा बना सकते हैं। एक लेनदेन प्रणाली को ध्यान में रखें। डेटा एक उपयोगकर्ता क्लास से एक आदेश क्लास, फिर एक इन्वेंटरी क्लास, और अंततः एक भुगतान गेटवे क्लास।
इस फ्लो को दृश्याकरण करने से पहचानने में मदद मिलती है:
- प्रवेश बिंदु: डेटा सिस्टम में कहाँ प्रवेश करता है? कौन सा क्लास प्रारंभिक अनुरोध को संभालता है?
- प्रसंस्करण परतें: कौन सी क्लासें डेटा को परिवर्तित करती हैं? क्या वैधता और गणना के लिए अलग-अलग क्लासें हैं?
- स्टोरेज लक्ष्य: डेटा कहाँ स्थायी रूप से संग्रहीत होता है? कौन सी क्लासें डेटाबेस एंटिटीज का प्रतिनिधित्व करती हैं?
- प्रतिलाभ मार्ग: परिणाम उपयोगकर्ता तक कैसे वापस यात्रा करता है? क्या
आदेशक्लास उपयोगकर्ता क्लास को पुष्टि ऑब्जेक्ट लौटाती है?उपयोगकर्ताक्लास?
जब इन फ्लो को मैप करते हैं, तो कार्डिनैलिटी पर ध्यान दें। कार्डिनैलिटी संबंध में शामिल उदाहरणों की संख्या को परिभाषित करती है। क्या यह एक-से-एक है? एक-से-बहुत? बहुत-से-बहुत? यह निर्धारित करता है कि डेटा कैसे प्राप्त और संगृहीत किया जाता है।
| कार्डिनैलिटी | नोटेशन | उदाहरण | डेटा फ्लो प्रभाव |
|---|---|---|---|
| एक-से-एक | 1 — 1 | व्यक्ति — पासपोर्ट | सीधे खोज। उच्च दक्षता। |
| एक-से-बहुत | 1 — N | ग्राहक — आदेश | पुनरावृत्ति आवश्यक है। सूची या ऐरे का प्रबंधन। |
| बहुत-से-बहुत | M — N | छात्र — पाठ्यक्रम | संयोजन तालिका या लिंकिंग क्लास की आवश्यकता होती है। |
🛡️ रखरखाव के लिए सर्वोत्तम प्रथाएँ
एक आरेख केवल तभी उपयोगी होता है जब वह सटीक रहे। जैसे-जैसे एप्लिकेशन विकसित होता है, आरेख को उसके साथ विकसित होना चाहिए। निरूपण को प्रभावी बनाए रखने के लिए यहाँ कुछ रणनीतियाँ हैं:
- पहले उच्च स्तर को बनाए रखें: प्राथमिक कक्षाओं से शुरू करें (उदाहरण के लिए,
उत्पाद,कार्ट) तकनीकी कक्षाओं में डूबने से पहले (उदाहरण के लिए,डेटाबेस कनेक्शन)। इससे आरेख में कार्यान्वयन विवरणों के साथ भारीपन नहीं बढ़ता है। - इंटरफेस का उपयोग करें: जब कई कक्षाएँ एक ही व्यवहार को लागू करती हैं, तो इंटरफेस का उपयोग करें। इससे स्पष्ट होता है कि डेटा प्रवाह इंटरफेस के अनुबंध पर निर्भर करता है, न कि विशिष्ट कार्यान्वयन पर। इससे निर्भरता कम होती है।
- संबंधित कक्षाओं को समूहित करें: एक ही मॉड्यूल से संबंधित कक्षाओं को समूहित करने के लिए पैकेज या नामस्थान का उपयोग करें। इससे तार्किक सीमाएँ बनती हैं और डेटा प्रवाह के प्रश्नों की सीमा सीमित होती है।
- प्रतिबंधों को दस्तावेज़ीकृत करें: व्यावसायिक नियमों के लिए आरेख में नोट जोड़ें जिन्हें दृश्य रूप से प्रस्तुत नहीं किया जा सकता है। उदाहरण के लिए, एक नोट में बताया जा सकता है कि एक
आदेश24 घंटों के बाद रद्द नहीं किया जा सकता है। - गहराई सीमित करें: संबंधों को बहुत गहराई से निर्मित करने से बचें। यदि एक कक्षा सीधे पांच अन्य कक्षाओं से बातचीत करती है, तो यह जांचें कि क्या यह बहुत जटिल है। उच्च निर्भरता अक्सर पुनर्गठन की आवश्यकता का संकेत होती है।
⚠️ मॉडलिंग में आम गलतियाँ
यहाँ तक कि अनुभवी वास्तुकार भी इन संरचनाओं को बनाते समय गलतियाँ करते हैं। आम गलतियों के बारे में जागरूक होने से एप्लिकेशन के एक स्पष्ट नक्शे के निर्माण में मदद मिलती है।
- जिम्मेदारियों का मिश्रण: एक कक्षा को एक चीज अच्छी तरह करनी चाहिए। यदि एक
उपयोगकर्ताकक्षा प्रमाणीकरण, प्रोफाइल अपडेट और ईमेल भेजने का ध्यान रखती है, तो डेटा प्रवाह जटिल हो जाता है। इन्हें अलग करेंप्रमाणीकरण सेवा,प्रोफाइल सेवा, औरईमेल सेवा. - नल संभाव्यता को नजरअंदाज करना: प्रत्येक विशेषता का एक परिभाषित अवस्था होनी चाहिए। क्या यह है
फ़ोन नंबरआवश्यक है? यदि यह वैकल्पिक है, तो डेटा प्रवाह में नल जांच को ध्यान में रखना होगा। इसका दृश्यीकरण रनटाइम त्रुटियों को रोकता है। - अतिरिक्त मॉडलिंग: प्रत्येक चर को आरेखित करने की आवश्यकता नहीं है। यदि एक चर एक अस्थायी स्थानीय गणना है, तो इसका संरचनात्मक आरेख में स्थान नहीं है। स्थायी अवस्था और मुख्य बातचीत पर ध्यान केंद्रित करें।
- स्थिर विधियों के अत्यधिक उपयोग: स्थिर विधियाँ अवस्था की कमी को इंगित करती हैं। कभी-कभी आवश्यक होने पर भी, उनके अत्यधिक उपयोग ऑब्जेक्ट-ओरिएंटेड प्रवाह को तोड़ देते हैं। डेटा स्वामित्व को स्पष्ट रखने के लिए इंस्टेंस विधियों के लिए उनका उपयोग कम किया जाना चाहिए।
🔄 विकास जीवनचक्र के साथ एकीकरण
वर्ग आरेख केवल डिज़ाइन चरण के लिए नहीं होते हैं। वे सॉफ्टवेयर विकास जीवनचक्र के दौरान सभी चरणों में भूमिका निभाते हैं।
योजना बनाते समय
कोड लिखने से पहले, आरेख स्टेकहोल्डर्स को दायरे को देखने में मदद करता है। यह गायब एंटिटी का जल्दी पता लगाने की अनुमति देता है। उदाहरण के लिए, यह समझना कि एक समीक्षा वर्ग की आवश्यकता है जब तक कि उत्पाद वर्ग को अंतिम रूप नहीं दिया गया है।
कोडिंग के दौरान
विकासकर्ता आरेख का उपयोग सही विशेषताओं के कार्यान्वयन सुनिश्चित करने के लिए संदर्भ के रूप में उपयोग करते हैं। यह कोड उत्पादन उपकरणों के लिए सच्चाई का स्रोत है, जो मॉडल के आधार पर वर्ग संरचनाओं को स्वचालित रूप से स्कैफोल्ड कर सकते हैं।
परीक्षण के दौरान
परीक्षक आरेख का उपयोग मॉड्यूल के बीच निर्भरता को समझने के लिए करते हैं। यदि रिपोर्टिंग मॉड्यूल में एक बग दिखाई देता है, तो आरेख दिखाता है कि कौन से ऊपरी वर्ग डेटा प्रदान करते हैं, जिससे खोज क्षेत्र संकुचित होता है।
रखरखाव के दौरान
जब नए विकासकर्ताओं को शामिल किया जाता है, तो आरेख प्रणाली का एक उच्च स्तरीय अवलोकन प्रदान करता है। यह कोड के हजारों पंक्तियों को पढ़ने की तुलना में डेटा के एप्लिकेशन के माध्यम से यात्रा करने के तरीके को तेजी से समझाता है।
🧩 वास्तविक दुनिया के परिदृश्य
आइए एक विशिष्ट परिदृश्य पर विचार करें: ई-कॉमर्स प्लेटफॉर्म। मुख्य संरचना कई महत्वपूर्ण क्षेत्रों को शामिल करती है।
- इन्वेंटरी क्षेत्र:शामिल करता है
उत्पाद,गोदाम, औरस्टॉक स्तर. आइटम जोड़ने, हटाने या अपडेट करने के लिए डेटा यहाँ आता है। - आदेश क्षेत्र: समावेश करता है
आदेश,आदेश आइटम, औरशिपिंग पता. जब कोई खरीदारी शुरू की जाती है तो डेटा यहाँ आता है। - भुगतान क्षेत्र: समावेश करता है
भुगतान लेनदेनऔरबिल. वित्तीय निपटान की पुष्टि करने के लिए डेटा यहाँ आता है। - उपयोगकर्ता क्षेत्र: समावेश करता है
ग्राहकऔरवॉलेट. पहचान और धन प्रबंधित करने के लिए डेटा यहाँ आता है।
इस संरचना में, आदेश क्लास मुख्य है। इसमें ग्राहक, एक सूची के साथ है ऑर्डरआइटमs, और एक का संदर्भ देता है भुगतान लेनदेन. डेटा प्रवाह अनुक्रमिक है: ग्राहक आइटम चुनता है -> ऑर्डर बनता है -> भुगतान प्रक्रिया में डाला जाता है -> स्टॉक अद्यतन किया जाता है। एक क्लास डायग्राम इस क्रम को संबंधों की श्रृंखला के रूप में दृश्यमान बनाता है।
इस दृश्यावली के बिना, एक विकासकर्ता गलती से इन्वेंटरी जांचे बिना ऑर्डर दर्ज करने या ऑर्डर की पुष्टि से पहले भुगतान प्रक्रिया करने की अनुमति दे सकता है। डायग्राम अपनी संरचना के माध्यम से तर्क को बल देता है।
🛠️ कार्यान्वयन और दस्तावेजीकरण
इन डायग्राम को बनाने में सटीकता और पठनीयता के बीच संतुलन बनाए रखना आवश्यक है। संरचना के दस्तावेजीकरण के समय सुनिश्चित करें कि नामकरण प्रणाली संगत हो। विशेषताओं के लिए camelCase का उपयोग करें और क्लासेस के लिए PascalCase का उपयोग करें। इस संगतता से डायग्राम पढ़ते समय मानसिक भार कम होता है।
इसके अलावा, संस्करण नियंत्रण बहुत महत्वपूर्ण है। डायग्राम फ़ाइल को कोडबेस के साथ संग्रहीत किया जाना चाहिए। यदि कोड में परिवर्तन होता है लेकिन डायग्राम में नहीं, तो डायग्राम प्राचीन दस्तावेजीकरण बन जाता है, जो कि कोई भी दस्तावेजीकरण न होने से भी बदतर है। कभी-कभी स्वचालित उपकरण कोड परिवर्तनों को डायग्राम में समायोजित कर सकते हैं, लेकिन तर्क अभी भी सही है या नहीं, इसकी जांच के लिए मैन्युअल समीक्षा आवश्यक रहती है।
🔍 विशेषताओं के माध्यम से डेटा प्रवाह का विश्लेषण
विशेषताएं डेटा के भंडारण के बर्तन हैं। एक क्लास डायग्राम में, विशेषता का प्रकार प्रवाह को निर्धारित करता है। उदाहरण के लिए, एक स्ट्रिंग विशेषता पाठ को रखती है, जबकि एक दिनांक विशेषता समय-संवेदनशील डेटा को रखती है। एक बूलियन विशेषता एक स्थिति को रखती है।
जब डेटा प्रवाह का नक्शा बनाते हैं, तो विशेषता के जीवनचक्र को ध्यान में रखें:
- निर्माण: विशेषता कैसे प्रारंभ की जाती है? क्या इसे कंस्ट्रक्टर में सेट किया जाता है?
- संशोधन: कौन से विधियां इस विशेषता को बदलती हैं? क्या यह पठन-केवल है?
- हटाना: इस विशेषता को कब हटाया जाता है? क्या यह संबंधित क्लासेस में कैस्केड हटाने को ट्रिगर करता है?
इन जीवनचक्रों को डायग्राम पर टिप्पणी करके, आप डेटा गतिशीलता की कहानी बनाते हैं। उदाहरण के लिए, एक स्थिति विशेषता को एक निश्चित स्थिति प्राप्त करने के बाद पठन-केवल चिह्नित करने से अनजाने अपडेट होने से बचाव होता है, जो कार्यप्रवाह को विकृत कर सकता है।
🚀 निष्कर्ष
क्लास डायग्राम के माध्यम से डेटा प्रवाह को दृश्यमान करना एक अनुशासन है जो सिस्टम स्थिरता और विकासकर्ता दक्षता में लाभ देता है। यह अमूर्त तर्क को एक भौतिक संरचना में बदल देता है जिसे समीक्षा, आलोचना और सुधार किया जा सकता है। मुख्य संरचना और संबंधों पर ध्यान केंद्रित करके, टीमें ऐसे एप्लिकेशन बना सकती हैं जो टिकाऊ, स्केलेबल और समझने में आसान हों।
इन डायग्राम को बनाने में लगाए गए प्रयास को कोडबेस के भविष्य के लिए निवेश माना जाना चाहिए। यह इरादे को स्पष्ट करता है, अस्पष्टता को कम करता है, और यह सुनिश्चित करता है कि एप्लिकेशन के माध्यम से बहने वाला डेटा अपने उद्देश्य को अप्रत्याशित विचलन के बिना पूरा करे। जैसे-जैसे प्रणालियां बढ़ती हैं, स्पष्ट नक्शों की आवश्यकता केवल उपयोगी नहीं, बल्कि जीवित रहने के लिए आवश्यक हो जाती है।