











ソフトウェアシステムは時間とともに複雑さを増していきます。単純なスクリプトから始まるものが、相互に作用するコンポーネントのネットワークへと拡大していきます。明確なマップがなければ、開発者は依存関係の迷宮の中をさまよってしまい、バグの原因やデータの行き先がはっきりしなくなります。このような状況で視覚的モデリングが不可欠になります。特に、クラス図はオブジェクト指向アプリケーションのアーキテクチャ設計図として機能します。クラスを列挙するだけではなく、データがシステム全体でどのように移動し、変換され、永続化されるかを示すのです。
アプリケーションのコア構造を理解するには、コードそのもの以上の視点が必要です。構文を無視し、論理、関係性、フローに注目する表現が必要です。クラス図の構築を習得することで、チームはボトルネックを予測し、責任を明確にし、ユーザーインターフェースからデータベースレイヤーにかけてデータの整合性を保つことができます。このガイドでは、視覚的デザインを通じてアプリケーション構造をマッピングするメカニズムについて探求します。
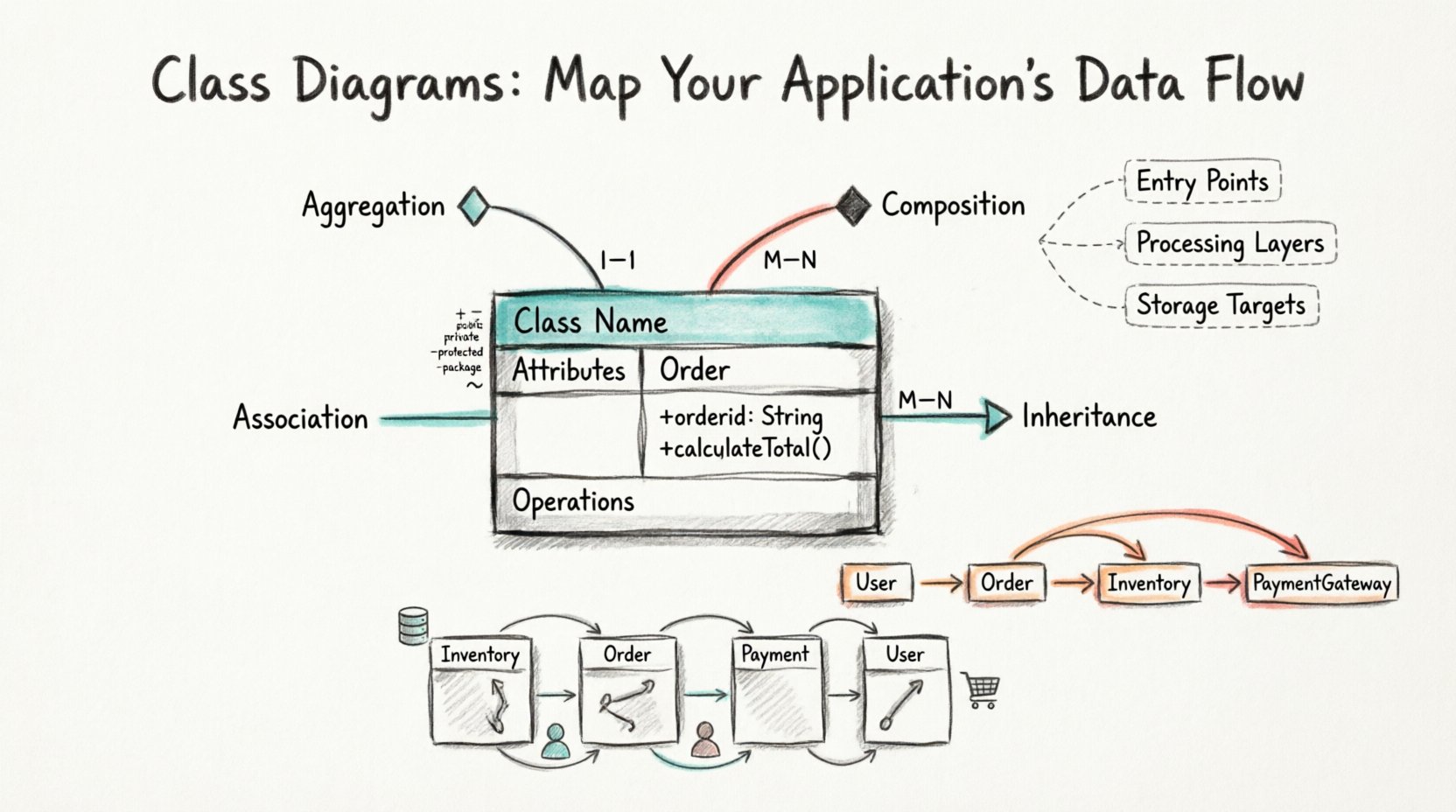
🧱 クラス図の基盤
クラス図は、統合モデル言語(UML)における静的構造図です。システムのクラス、その属性、操作(またはメソッド)、およびオブジェクト間の関係を示すことで、システムの構造を記述します。シーケンス図が時間の経過に伴う動的動作を捉えるのに対し、クラス図は特定の瞬間におけるシステム設計のスナップショットを提供します。
なぜこのスナップショットが価値があるのでしょうか?それは設計と実装の間の契約として機能するからです。開発者がコードを書くとき、実際には図で約束されたことを実現しているのです。図に2つのクラスの特定の関係が示されているならば、コードもそのつながりを反映しなければなりません。この整合性により、技術的負債が削減され、システムが緩くつながったファイルの集まりになってしまうのを防ぐことができます。
🏗️ クラスの構造
データフローを効果的に可視化するには、まずクラスを構成する要素を理解する必要があります。標準的なクラス図のボックスは通常、3つのセクションに分けられます:
- クラス名: 上部に位置し、システム内のエンティティを表す名詞が通常記載されます。大文字で記述する必要があります(例:
顧客または注文処理エンジン). - 属性: 中央のセクションには、クラスが保持するデータがリストアップされます。これらはプロパティや状態変数です。例として、
メールアドレス,残高、またはステータス. - 操作: 下部のセクションには、クラスが実行できるメソッドや関数が詳細に記載されます。これらは動詞に相当します。例として、
計算総額(),通知を送信()、またはプロフィールを更新().
各属性および操作には、それがシステムの他の部分とどのように相互作用するかを規定する可視性修飾子が割り当てられます。これらの修飾子を理解することは、データフローを追跡する上で不可欠です。
| 修飾子 | 記号 | アクセスレベル | データフローへの影響 |
|---|---|---|---|
| パブリック | + |
すべてのクラスからアクセス可能 | データは他のすべてのクラスから読み取られたり変更されたりできます。開放的な経路を形成します。 |
| プライベート | - |
クラス内部でのみアクセス可能 | データはカプセル化されています。フローはパブリックメソッドを通じて行われなければなりません。 |
| プロテクト | # |
サブクラスからのみアクセス可能 | データは継承階層内で流れますが、外部クラスからは隠されています。 |
| パッケージ | ~ |
パッケージ内でのみアクセス可能 | 関連するモジュール間ではデータが自由に流れますが、それ以外の場所では制限されます。 |
🔗 関係性と関連の定義
クラスは孤立して存在することはめったにありません。それらは相互作用の網目の中に存在します。クラスボックスをつなぐ線は関係性を表しています。これらの関係性は、データがどのように渡されるか、依存関係がどのように形成されるかを定義します。関係性を誤解すると、一つのクラスを変更すると別のクラスが壊れるという強い結合が生じる可能性があります。
視覚化すべき主な関係性は4種類あります:
- 関連: 2つのクラスの間の単純なリンクで、お互いを認識していることを示します。これは参照の双方向または単方向の流れを表します。たとえば、
マネージャーは従業員. - 集約: 特定の関連の種類で、部分が全体から独立して存在できる「全体-部分」関係を表す。もし
チームが解体されると、選手オブジェクトは依然として存在する。 - 合成:部分が全体なしでは存在できない、集約のより強い形態。もし
家が削除されると、部屋オブジェクトは存在しなくなる。これは厳密なライフサイクル依存関係を意味する。 - 継承(一般化):「は」関係を表す。
車両は自動車とトラックの親である。データは子から親へ流れ、属性とメソッドを継承する。
📈 データフローのダイナミクスを可視化する
クラス図は静的であるが、動的な振る舞いを示唆している。クラス間の線をたどることで、データの潜在的な経路をマッピングできる。取引システムを考えてみよう。データはユーザークラスから注文クラスへ、次に在庫クラスへ、最後に決済ゲートウェイクラスへ流れる可能性がある。
このフローを可視化することで、次を特定しやすくなります:
- エントリポイント: データはシステムのどこから入力されますか?初期のリクエストを処理するクラスはどれですか?
- 処理レイヤー: データを変換するクラスはどれですか?検証と計算のための別々のクラスはありますか?
- ストレージターゲット: データはどこに永続化されますか?データベースエンティティを表すクラスはどれですか?
- 戻りパス: 結果はユーザーに戻る際にどのように移動しますか?
注文クラスは確認オブジェクトをユーザークラスに返しますか?
これらのフローをマッピングする際には、基数に注意を払ってください。基数は関係に含まれるインスタンスの数を定義します。1対1ですか?1対多ですか?多対多ですか?これはデータの取得および集約方法を決定します。
| 基数 | 表記法 | 例 | データフローへの影響 |
|---|---|---|---|
| 1対1 | 1 — 1 | 個人 — パスポート | 直接検索。高い効率性。 |
| 1対多 | 1 — N | 顧客 — 注文 | 反復処理が必要。リストまたは配列の処理。 |
| 多対多 | M — N | 学生 — 授業 | 中間テーブルまたはリンククラスが必要です。 |
🛡️ メンテナビリティのためのベストプラクティス
図は正確である限りにおいてのみ有用です。アプリケーションが進化するにつれて、図もそれに合わせて進化しなければなりません。視覚化の効果を保つための戦略を以下に示します:
- まずは高レベルで保つ:まずドメインクラス(例:
Product,Cart)から始め、インフラストラクチャクラス(例:DatabaseConnection)に飛び込む前に。これにより、実装の詳細で図がごちゃごちゃになるのを防ぎます。 - インターフェースを使用する:複数のクラスが同じ振る舞いを実装する場合、インターフェースを使用します。これにより、データフローがインターフェースの契約に依存していることが明確になり、具体的な実装に依存しているわけではないことがわかります。依存関係を軽減できます。
- 関連するクラスをグループ化する:同じモジュールに属するクラスをパッケージまたは名前空間でグループ化します。これにより論理的な境界が作られ、データフローの照会範囲が制限されます。
- 制約を文書化する:視覚的に表現できないビジネスルールについて、図に注記を追加します。たとえば、注記に「
OrderOrder - 深さを制限する:関係性をあまり深くネストしないようにします。あるクラスが直接5つの他のクラスとやり取りしている場合、複雑さが過ぎていないか検討してください。高い結合度は、リファクタリングの必要性を示すことが多いです。
⚠️ モデリングにおける一般的な落とし穴
経験豊富なアーキテクトですら、これらの構造を描く際に誤りを犯します。一般的な誤りに気づくことで、アプリケーションのより明確なマップを作成できます。
- 責任の混同:クラスは一つのことをよく行うべきです。もし
Userクラスが認証、プロフィール更新、メール送信をすべて処理している場合、データフローは複雑になります。これらをAuthService,ProfileService、およびEmailService. - null可能性を無視する: すべての属性は明確な状態を持つべきです。 は
phoneNumber必須ですか? オプションの場合、データフローはnullチェックを考慮しなければなりません。これを可視化することで、実行時エラーを防ぐことができます。 - 過剰なモデル化: すべての変数を描く必要はありません。一時的なローカル計算の変数は、構造図に含まれるべきではありません。永続的な状態と主要な相互作用に注目してください。
- 静的メソッドの乱用: 静的メソッドは状態の欠如を示唆します。たまに必要になることもありますが、過剰に使用するとオブジェクト指向の流れが崩れます。明確なデータ所有権を維持するために、インスタンスメソッドに優先して使用を最小限に抑えるべきです。
🔄 開発ライフサイクルとの統合
クラス図は設計フェーズだけのものではありません。ソフトウェア開発ライフサイクル全体で役割を果たします。
計画段階
1行のコードを書く前にも、図はステークホルダーが範囲を可視化するのを助けます。欠落しているエンティティの早期発見が可能になります。たとえば、Review クラスが必要であることに気づくこと。Product クラスが最終化される前に。
コーディング段階
開発者は、正しい属性を実装しているかを確認するために図を参照します。コード生成ツールにとって真実のソースとして機能し、モデルに基づいてクラス構造を自動的にスケルトン化できます。
テスト段階
テスト担当者は、モジュール間の依存関係を理解するために図を使用します。もしReporting モジュールにバグが発生した場合、図はどの上流クラスがデータを提供しているかを示し、検索範囲を絞り込みます。
保守段階
新規開発者をオンボーディングする際、図はシステムの高レベルな概要を提供します。数千行のコードを読むよりも、データがアプリケーション内でどのように流れているかを素早く説明できます。
🧩 実際のシナリオ
特定のシナリオを検討しましょう:ECプラットフォームです。コア構造にはいくつかの主要なドメインが含まれます。
- 在庫ドメイン:包含する
製品,倉庫、および在庫数。在庫の追加、削除、または更新のためのデータがここに流れ込む。 - 注文ドメイン: を含む
注文,注文項目、および配送先住所。購入が開始されたときにデータがここに流れ込む。 - 決済ドメイン: を含む
決済取引および請求書。財務決済の確認のためにデータがここに流れ込む。 - ユーザー・ドメイン: を含む
顧客およびウォレット。本人確認情報および資金の管理のためのデータがここに流れ込む。
この構造では、注文クラスが中心となる。これは顧客、リストを含みますOrderItem、および参照しますPaymentTransaction。データフローは順次的です:カスタマーがアイテムを選択 -> 注文が作成 -> 支払いが処理 -> 在庫が更新。クラス図はこの順序を関連の連鎖として可視化します。
この可視化がなければ、開発者が在庫の確認なしに注文を可能にしたり、注文が確認される前に対応する支払いを処理してしまう可能性があります。図はその構造を通じて論理を強制します。
🛠️ 実装とドキュメント化
これらの図を作成するには、正確さと可読性のバランスが必要です。構造をドキュメント化する際は、命名規則が一貫していることを確認してください。属性にはcamelCase、クラスにはPascalCaseを使用してください。この一貫性により、図を読む際の認知負荷が軽減されます。
さらに、バージョン管理は不可欠です。図ファイルはコードベースと一緒に保管するべきです。コードが変更されても図が更新されない場合、図は陳腐化したドキュメントとなり、まったくドキュメントがないよりも悪くなります。自動化ツールでコードの変更を図に同期できる場合もありますが、論理が依然として成立していることを確認するために手動でのレビューは必要です。
🔍 属性を通じたデータフローの分析
属性はデータの格納容器です。クラス図では、属性の型がフローを決定します。たとえば、String属性はテキストを保持し、Date属性は時間に依存するデータを保持します。Boolean属性は状態を保持します。
データフローをマッピングする際は、属性のライフサイクルを検討してください:
- 作成:属性はどのように初期化されますか?コンストラクタで設定されますか?
- 変更:どのメソッドがこの属性を変更しますか?読み取り専用ですか?
- 削除:この属性はいつ削除されますか?関連クラスで連鎖削除を引き起こしますか?
これらのライフサイクルを図に注釈することで、データ移動の物語が作成されます。たとえば、ある状態に達した後にstatus属性を読み取り専用としてマークすることで、ワークフローを破壊する可能性のある誤った更新を防ぎます。
🚀 結論
クラス図を通じたデータフローの可視化は、システムの安定性と開発者の生産性に大きな利益をもたらす分野です。抽象的な論理を、レビュー、批判、改善が可能な具体的な構造に変換します。コア構造と関係性に注目することで、堅牢でスケーラブルかつ理解しやすいアプリケーションの構築が可能になります。
これらの図を描くために費やされた努力は、コードベースの将来への投資です。意図を明確にし、曖昧さを減らし、アプリケーション内を流れているデータが予期しない経路を取ることなく目的を果たすことを保証します。システムが拡大するにつれて、明確なマップの必要性は単なる便利さではなく、存続のための必須事項になります。