











In modern software architecture, the disconnect between the object-oriented model used in application code and the relational model used in persistent storage is a persistent challenge. Developers frequently encounter situations where the visual representation of data structures in a class diagram diverges significantly from the physical layout of tables and columns in the database schema. This discrepancy is not merely cosmetic; it represents a fundamental architectural friction that can lead to data integrity issues, performance bottlenecks, and increased maintenance costs. Understanding the root causes of these mismatches is essential for building robust, scalable systems.
When a class diagram does not align with the underlying database schema, it creates an impedance mismatch. This term describes the set of difficulties inherent in using object-oriented programming languages to solve problems that exist in a relational database environment. While the object world operates on instances, methods, and inheritance, the database world relies on sets, rows, and foreign keys. Bridging this gap requires deliberate design decisions and rigorous validation.
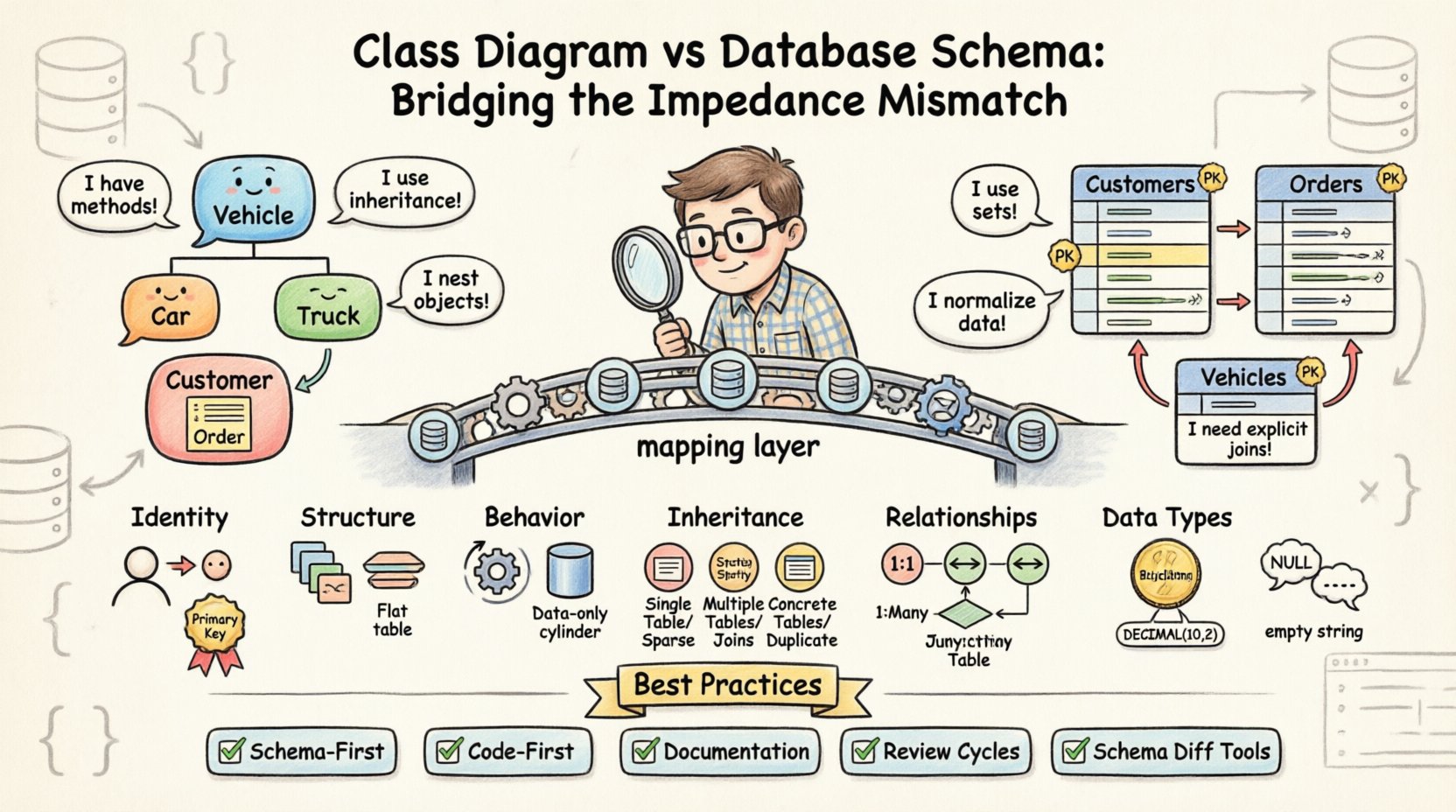
🔄 The Core Tension: Objects vs. Tables
The fundamental difference lies in the philosophy of data storage. Object-oriented classes encapsulate state and behavior together. In contrast, relational databases normalize data to reduce redundancy. This divergence creates several specific areas where the two models struggle to synchronize.
- Identity: Objects are identified by memory reference or a unique object identifier during runtime. Databases use primary keys, often auto-incrementing integers or UUIDs, which exist independently of the application lifecycle.
- Structure: A class can have complex nested objects, collections, and circular references. A database table cannot natively store a nested object without flattening it or creating a separate table.
- Behavior: Classes contain methods that manipulate data. Database tables contain data only; any logic must be handled via stored procedures or outside the database layer.
When developers attempt to map these two paradigms directly without careful abstraction, errors occur. The mapping layer often acts as a translator, but no translator is perfect. Nuances in logic, null handling, and type conversion are frequently lost in translation.
🏗️ Structural Discrepancies in Mapping
One of the most common sources of mismatch involves how relationships between entities are handled. In a class diagram, relationships are often depicted as simple lines indicating associations. In a database schema, these associations require explicit foreign key constraints and often intermediate join tables.
Inheritance Hierarchies
Object-oriented systems thrive on inheritance. A Vehicle class might have subclasses like Car and Truck. This allows for polymorphism and code reuse. However, relational databases do not support inheritance natively. To model this, engineers must choose between specific strategies, each with trade-offs.
- Table Per Hierarchy: A single table stores all data for the parent and all subclasses. This is simple but leads to sparse columns and null values when subclass-specific fields are used.
- Table Per Subclass: Each class gets its own table. The parent table holds common attributes, while child tables hold specific ones linked by a foreign key. This increases the complexity of joins required to retrieve a full object.
- Table Per Concrete Class: Every concrete class gets a full table containing all attributes. This avoids joins but requires duplicating common data across multiple tables.
If the class diagram shows a clear inheritance tree but the database schema uses a single flat table, the schema does not match the logical model. This can lead to confusion during maintenance, as developers might expect specific columns that do not exist due to the flattening strategy.
Association and Aggregation
Consider a Customer class with a collection of Order objects. In the class diagram, this is a one-to-many relationship. In the database, this is represented by a foreign key column in the Orders table referencing the Customers table. However, the direction of the relationship is often where mismatches occur.
- Many-to-Many Relationships: A class diagram might show
StudentandCourselinked by a many-to-many association. The database requires a third table, often called a junction or bridge table, to resolve this. If the schema omits this table, the relationship cannot be enforced. - Cardinality: A class diagram might indicate an optional relationship (0..*). The database schema must reflect this with nullable foreign keys. If the schema enforces a NOT NULL constraint, it contradicts the class definition.
- Cascading Deletes: In code, deleting a parent object might automatically remove children. In the database, this requires cascading delete rules. If these are not configured, orphaned records remain, breaking data integrity.
🛡️ Data Integrity and Type Mismatches
Beyond structure, the actual data types defined in the class often fail to align with database column types. While modern systems offer extensive mapping capabilities, edge cases frequently cause issues.
Nullability Constraints
In object-oriented languages, a field is often nullable by default unless explicitly initialized. In relational databases, the NOT NULL constraint is a performance and integrity optimization. A mismatch here leads to runtime exceptions.
- Default Values: A class might assume a string field defaults to an empty string. The database might default it to NULL. Code expecting an empty string will crash if it receives NULL.
- Validation: Application-level validation might allow a field to be null. The database schema rejects it. This creates a conflict between the business logic and the storage layer.
Numeric Precision and Scale
Financial data requires high precision. A class might use a BigDecimal or Decimal type to handle currency. The database must support a corresponding column type with defined precision and scale.
- Truncation: If the database column is defined as
DECIMAL(10, 2)but the application logic attempts to storeDECIMAL(10, 4), data loss occurs silently or via an error. - Float vs. Decimal: Using floating-point types for money is a common anti-pattern. While a class might use
doublefor performance, the database should enforce exact arithmetic to prevent rounding errors in accounting.
🏷️ Naming Conventions and Identity
Consistency in naming is vital for maintainability. However, the conventions used in programming languages often differ from those used in database management systems.
Snake_case vs. CamelCase
Java and C# typically use camelCase for class properties and field names. Many relational databases prefer snake_case for table and column names. While mapping tools often handle this conversion automatically, manual schema creation might violate this rule.
- Case Sensitivity: Some databases are case-sensitive, while others are not. A column named
FirstNamein the database might be queried asfirstnamein code, leading to errors depending on the server configuration. - Reserved Words: Class properties might use names that are reserved keywords in the database language, such as
OrderorUser. These require quoting or aliasing, which complicates the query generation.
Primary Keys and Foreign Keys
The choice of primary key strategy is another common friction point. Classes often rely on natural keys (like a username or email) or surrogate keys (like an auto-generated ID).
- Natural Keys: Using a business value as a primary key can make the schema rigid. If the business rule changes (e.g., an email address changes), the foreign key references must be updated everywhere.
- Surrogate Keys: Using an auto-incrementing ID is safer for joins but introduces an extra column that has no semantic meaning in the business logic.
⚡ Performance Trade-offs
Designing a schema that matches a class diagram often ignores performance implications. Theoretical correctness does not always equate to operational efficiency.
Normalization vs. Denormalization
Class diagrams often reflect normalized data structures to avoid redundancy. However, database performance sometimes benefits from denormalization to reduce the number of joins required during read operations.
- Join Complexity: A complex class hierarchy might require multiple joins to fetch a single object. In high-traffic systems, this can degrade response times significantly.
- Caching: Denormalized data can be cached more easily. If the schema is too normalized, the application layer must perform complex reconstruction logic, negating the benefits of caching.
Indexing Strategies
Indexes are defined at the database level to speed up queries, but they are rarely visible in a class diagram. The absence of index definitions in the schema design can lead to slow queries.
- Foreign Key Indexes: Foreign key columns should ideally be indexed to speed up join operations. If the schema omits these indexes, lookups on related data will scan entire tables.
- Search Patterns: If the application frequently searches by a specific attribute, a database index is required. If the class diagram highlights this attribute but the schema does not index it, performance will suffer.
🔍 Detecting and Resolving Mismatches
Identifying where the schema diverges from the model is the first step toward resolution. This process requires a combination of automated tools and manual auditing.
Schema Diff Tools
Automated comparison utilities can highlight differences between the expected state (derived from the class diagram or code) and the actual state (the physical database).
- Change Detection: These tools can identify missing columns, altered data types, or removed constraints.
- Migration Scripts: They can generate the SQL required to bring the schema in line with the model, reducing manual error.
Manual Auditing
Automation is helpful, but human review is necessary for complex logic. Reviewers should verify the following:
- Are all class fields represented by database columns?
- Do the data types match exactly, including length and precision?
- Are relationships properly constrained with foreign keys?
- Are naming conventions consistent across the board?
Common Mapping Scenarios and Potential Issues
| Mapping Scenario | Class Diagram Representation | Database Schema Representation | Potential Issue |
|---|---|---|---|
| One-to-One | Single line connecting two classes | Foreign key in one table (unique constraint) | Missing unique constraint allows duplicates. |
| One-to-Many | List collection in parent class | Foreign key in child table | Missing index on foreign key slows queries. |
| Many-to-Many | Link class or association | Junction table with two foreign keys | Junction table omitted causes data loss. |
| Inheritance | Extends keyword or arrow | Single table with NULLs OR multiple tables | Sparsity in single table or complex joins in multiple. |
📝 Best Practices for Alignment
To minimize future friction, teams should adopt strategies that prioritize alignment between the logical and physical models. This involves communication and process, not just technology.
- Schema-First Approach: Define the database schema before writing the application code. This ensures the storage layer dictates the constraints, and the code must adapt to them.
- Code-First Approach: Define the classes first, then generate the schema. This is faster for development but risks creating an inefficient physical structure that is hard to optimize later.
- Documentation: Maintain a living document that maps class properties to database columns. This serves as a single source of truth for developers and database administrators.
- Review Cycles: Include database schema reviews in the code review process. No code should be merged without verifying that the migration scripts match the class changes.
🛠️ Handling Legacy Systems
Not all projects start with a blank slate. Many organizations must deal with legacy databases that do not match current class diagrams. Refactoring in this context requires caution.
- Strangler Fig Pattern: Gradually move new functionality to a new schema while the old system remains operational. This allows the class diagram to evolve without breaking existing integrations.
- Views and Staging: Create database views to present the data in a format that matches the new class diagram without altering the underlying tables immediately.
- Incremental Migration: Move data in batches. Verify integrity after each batch before proceeding to the next. This minimizes the risk of data corruption during the transition.
🚀 Moving Forward
The gap between the class diagram and the database schema is an inherent challenge in software engineering. It arises from the fundamental differences between how computers process logic and how they store information. There is no perfect solution that eliminates this friction entirely, but there are strategies to manage it effectively.
By understanding the nuances of inheritance, relationships, data types, and naming conventions, teams can reduce the frequency of errors. Regular auditing and the use of automated tools help maintain synchronization over time. The goal is not to make the database look exactly like the code, but to ensure that the mapping between them is transparent, consistent, and performant. When the physical storage aligns with the logical design, development becomes more predictable, and the system remains stable under load.