










Dans l’architecture logicielle moderne, le décalage entre le modèle orienté objet utilisé dans le code de l’application et le modèle relationnel utilisé pour le stockage persistant constitue un défi persistant. Les développeurs rencontrent fréquemment des situations où la représentation visuelle des structures de données dans un diagramme de classes diverge fortement de la disposition physique des tables et des colonnes dans le schéma de base de données. Ce désaccord n’est pas seulement esthétique ; il représente une friction architecturale fondamentale susceptible de provoquer des problèmes d’intégrité des données, des goulets d’étranglement de performance et des coûts de maintenance accrus. Comprendre les causes profondes de ces incohérences est essentiel pour concevoir des systèmes robustes et évolutifs.
Lorsqu’un diagramme de classes ne correspond pas au schéma de base de données sous-jacent, cela crée un désaccord d’impédance. Ce terme décrit l’ensemble des difficultés inhérentes à l’utilisation de langages de programmation orientés objet pour résoudre des problèmes existant dans un environnement de base de données relationnelles. Alors que le monde des objets fonctionne sur des instances, des méthodes et de l’héritage, le monde des bases de données repose sur des ensembles, des lignes et des clés étrangères. Comblant cet écart exige des décisions de conception réfléchies et une validation rigoureuse.
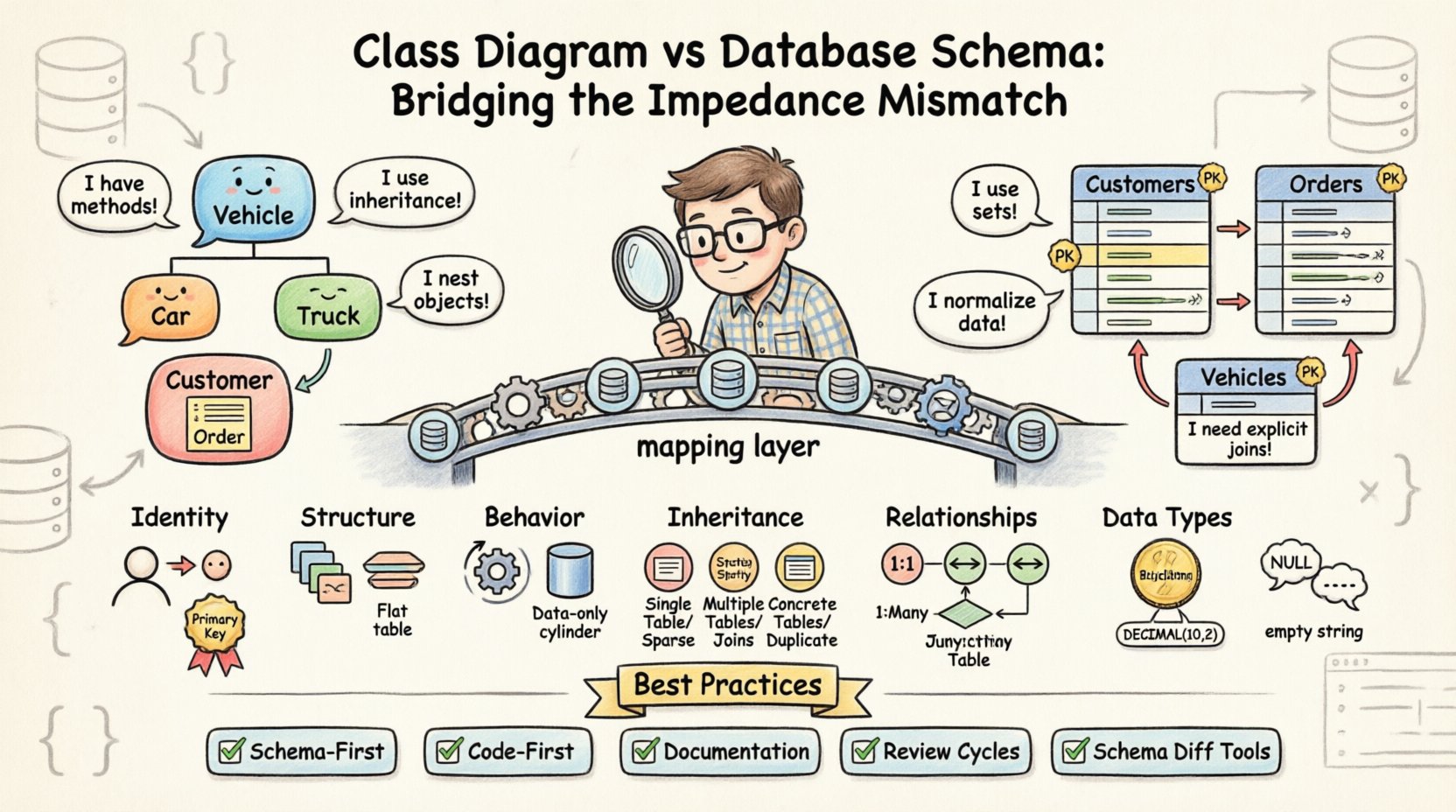
🔄 La tension fondamentale : Objets vs. Tables
La différence fondamentale réside dans la philosophie du stockage des données. Les classes orientées objet encapsulent l’état et le comportement ensemble. En revanche, les bases de données relationnelles normalisent les données afin de réduire la redondance. Ce décalage crée plusieurs domaines spécifiques où les deux modèles peinent à s’aligner.
- Identité :Les objets sont identifiés par une référence mémoire ou un identifiant unique d’objet pendant l’exécution. Les bases de données utilisent des clés primaires, souvent des entiers auto-incrémentés ou des UUID, qui existent indépendamment du cycle de vie de l’application.
- Structure :Une classe peut contenir des objets imbriqués complexes, des collections et des références circulaires. Une table de base de données ne peut pas stocker nativement un objet imbriqué sans le platifier ou créer une table séparée.
- Comportement :Les classes contiennent des méthodes qui manipulent les données. Les tables de base de données ne contiennent que des données ; toute logique doit être gérée via des procédures stockées ou en dehors du niveau de la base de données.
Lorsque les développeurs tentent de mapper directement ces deux paradigmes sans abstraction soigneuse, des erreurs surviennent. La couche de mapping agit souvent comme un traducteur, mais aucun traducteur n’est parfait. Les subtilités de la logique, la gestion des valeurs nulles et la conversion de types sont fréquemment perdues dans la traduction.
🏗️ Incohérences structurelles dans le mapping
L’une des sources les plus courantes d’incohérence concerne la manière dont les relations entre entités sont gérées. Dans un diagramme de classes, les relations sont souvent représentées par des lignes simples indiquant des associations. Dans un schéma de base de données, ces associations nécessitent des contraintes de clés étrangères explicites et souvent des tables de jointure intermédiaires.
Hiérarchies d’héritage
Les systèmes orientés objet prospèrent grâce à l’héritage. Une Véhicule peut avoir des sous-classes telles que Voiture et Camion. Cela permet la polymorphisme et la réutilisation du code. Toutefois, les bases de données relationnelles ne supportent pas nativement l’héritage. Pour modéliser cela, les ingénieurs doivent choisir entre des stratégies spécifiques, chacune comportant des compromis.
- Table par hiérarchie :Une seule table stocke toutes les données du parent et de toutes les sous-classes. C’est simple, mais cela entraîne des colonnes creuses et des valeurs nulles lorsque des champs spécifiques à la sous-classe sont utilisés.
- Table par sous-classe :Chaque classe obtient sa propre table. La table parente contient les attributs communs, tandis que les tables enfants contiennent les attributs spécifiques, liés par une clé étrangère. Cela augmente la complexité des jointures nécessaires pour récupérer un objet complet.
- Table par classe concrète :Chaque classe concrète obtient une table complète contenant tous les attributs. Cela évite les jointures, mais nécessite la duplication des données communes sur plusieurs tables.
Si le diagramme de classes montre une arborescence d’héritage claire, mais que le schéma de base de données utilise une seule table plate, le schéma ne correspond pas au modèle logique. Cela peut entraîner de la confusion lors de la maintenance, car les développeurs pourraient s’attendre à des colonnes spécifiques qui n’existent pas en raison de la stratégie de platification.
Association et agrégation
Considérez une Client classe avec une collection de Commande objets. Dans le diagramme de classe, il s’agit d’une relation un-à-plusieurs. Dans la base de données, cela est représenté par une colonne de clé étrangère dans la table Commandes qui fait référence à la table Clients table. Cependant, c’est souvent dans le sens de la relation que se produisent les incohérences.
- Relations plusieurs-à-plusieurs : Un diagramme de classe pourrait montrer
ÉtudiantetCoursreliés par une association plusieurs-à-plusieurs. La base de données nécessite une troisième table, souvent appelée table de jonction ou table de pont, pour résoudre cela. Si le schéma omet cette table, la relation ne peut pas être appliquée. - Cardinalité : Un diagramme de classe pourrait indiquer une relation facultative (0..*). Le schéma de base de données doit refléter cela avec des clés étrangères pouvant être nulles. Si le schéma impose une contrainte NOT NULL, cela contredit la définition de la classe.
- Suppressions en cascade : Dans le code, la suppression d’un objet parent pourrait supprimer automatiquement les enfants. Dans la base de données, cela nécessite des règles de suppression en cascade. Si celles-ci ne sont pas configurées, des enregistrements orphelins restent, compromettant l’intégrité des données.
🛡️ Intégrité des données et incompatibilités de type
Au-delà de la structure, les types de données réels définis dans la classe échouent souvent à s’aligner sur les types de colonnes de la base de données. Bien que les systèmes modernes offrent des capacités d’association étendues, des cas limites provoquent fréquemment des problèmes.
Contraintes de nullité
Dans les langages orientés objet, un champ est souvent nullable par défaut, sauf initialisation explicite. Dans les bases de données relationnelles, la contrainte NOT NULL est une optimisation de performance et d’intégrité. Un désaccord ici entraîne des exceptions à l’exécution.
- Valeurs par défaut : Une classe pourrait supposer qu’un champ chaîne a pour valeur par défaut une chaîne vide. La base de données pourrait le définir par défaut comme NULL. Le code qui s’attend à une chaîne vide planterait si il reçoit NULL.
- Validation : La validation au niveau de l’application pourrait autoriser un champ à être nul. Le schéma de base de données le rejette. Cela crée un conflit entre la logique métier et la couche de stockage.
Précision et échelle numériques
Les données financières exigent une grande précision. Une classe pourrait utiliser un BigDecimal ou Décimal type pour gérer la monnaie. La base de données doit prendre en charge un type de colonne correspondant avec une précision et une échelle définies.
- Troncature : Si la colonne de la base de données est définie comme
DÉCIMAL(10, 2)mais la logique de l’application tente de stockerDÉCIMAL(10, 4), une perte de données se produit silencieusement ou via une erreur. - Flottant par rapport à Décimal : Utiliser des types à virgule flottante pour la monnaie est un anti-pattern courant. Bien qu’une classe puisse utiliser
doublepour des raisons de performance, la base de données doit imposer des calculs exacts afin d’éviter les erreurs d’arrondi en comptabilité.
🏷️ Conventions de nommage et d’identité
La cohérence dans le nommage est essentielle pour la maintenabilité. Cependant, les conventions utilisées dans les langages de programmation diffèrent souvent de celles utilisées dans les systèmes de gestion de bases de données.
Snake_case par rapport à CamelCase
Java et C# utilisent généralement camelCase pour les propriétés de classe et les noms de champs. De nombreux systèmes de bases de données relationnelles préfèrent snake_case pour les noms de tables et de colonnes. Bien que les outils de mappage gèrent souvent cette conversion automatiquement, la création manuelle du schéma pourrait violer cette règle.
- Sensibilité à la casse : Certaines bases de données sont sensibles à la casse, tandis que d’autres ne le sont pas. Une colonne nommée
FirstNamedans la base de données pourrait être interrogée commefirstnamedans le code, ce qui peut entraîner des erreurs selon la configuration du serveur. - Mots réservés : Les propriétés de classe pourraient utiliser des noms qui sont des mots-clés réservés dans le langage de la base de données, tels que
OrderouUser. Ces noms nécessitent des guillemets ou des alias, ce qui complique la génération des requêtes.
Clés primaires et clés étrangères
Le choix de la stratégie de clé primaire est un autre point de friction courant. Les classes comptent souvent sur des clés naturelles (comme un nom d’utilisateur ou une adresse e-mail) ou des clés de substitution (comme un ID généré automatiquement).
- Clés naturelles :Utiliser une valeur métier comme clé primaire peut rendre le schéma rigide. Si la règle métier change (par exemple, une adresse e-mail change), les références de clés étrangères doivent être mises à jour partout.
- Clés de substitution :Utiliser un ID auto-incrémenté est plus sûr pour les jointures, mais introduit une colonne supplémentaire qui n’a pas de sens sémantique dans la logique métier.
⚡ Compromis de performance
Concevoir un schéma qui correspond à un diagramme de classes ignore souvent les implications de performance. La correction théorique ne correspond pas toujours à une efficacité opérationnelle.
Normalisation vs. Dénormalisation
Les diagrammes de classes reflètent souvent des structures de données normalisées pour éviter la redondance. Toutefois, les performances de la base de données peuvent parfois bénéficier de la dénormalisation afin de réduire le nombre de jointures nécessaires lors des opérations de lecture.
- Complexité des jointures :Une hiérarchie de classes complexe peut nécessiter plusieurs jointures pour récupérer un seul objet. Dans les systèmes à fort trafic, cela peut dégrader considérablement les temps de réponse.
- Mise en cache :Les données dénormalisées peuvent être mises en cache plus facilement. Si le schéma est trop normalisé, la couche application doit effectuer une logique de reconstruction complexe, annulant ainsi les avantages de la mise en cache.
Stratégies d’indexation
Les index sont définis au niveau de la base de données pour accélérer les requêtes, mais ils sont rarement visibles dans un diagramme de classes. L’absence de définitions d’index dans la conception du schéma peut entraîner des requêtes lentes.
- Index des clés étrangères :Les colonnes de clés étrangères devraient idéalement être indexées pour accélérer les opérations de jointure. Si le schéma omet ces index, les recherches sur les données associées scanneront entièrement les tables.
- Schémas de recherche : Si l’application recherche fréquemment par un attribut spécifique, un index de base de données est nécessaire. Si le diagramme de classes met en évidence cet attribut mais que le schéma ne l’indexe pas, les performances en pâtiront.
🔍 Détection et résolution des incohérences
Identifier où le schéma diverge du modèle est la première étape vers la résolution. Ce processus nécessite une combinaison d’outils automatisés et d’audits manuels.
Outils de comparaison de schémas
Les outils de comparaison automatisés peuvent mettre en évidence les différences entre l’état attendu (déduit du diagramme de classes ou du code) et l’état réel (la base de données physique).
- Détection des modifications : Ces outils peuvent identifier les colonnes manquantes, les types de données modifiés ou les contraintes supprimées.
- Scripts de migration : Ils peuvent générer le SQL nécessaire pour aligner le schéma sur le modèle, réduisant ainsi les erreurs manuelles.
Audit manuel
L’automatisation est utile, mais une revue humaine est nécessaire pour les logiques complexes. Les validateurs doivent vérifier ce qui suit :
- Tous les champs de classe sont-ils représentés par des colonnes de base de données ?
- Les types de données correspondent-ils exactement, y compris la longueur et la précision ?
- Les relations sont-elles correctement contraintes à l’aide de clés étrangères ?
- Les conventions de nommage sont-elles cohérentes dans l’ensemble ?
Scénarios courants de mappage et problèmes potentiels
| Scénario de mappage | Représentation du diagramme de classes | Représentation du schéma de base de données | Problème potentiel |
|---|---|---|---|
| Un-à-un | Ligne unique reliant deux classes | Clé étrangère dans une table (contrainte d’unicité) | L’absence de contrainte d’unicité permet les doublons. |
| Un-à-plusieurs | Collection de liste dans la classe parente | Clé étrangère dans la table enfant | L’absence d’index sur la clé étrangère ralentit les requêtes. |
| Plusieurs-à-plusieurs | Classe de lien ou association | Table de jonction avec deux clés étrangères | L’omission de la table de jonction entraîne une perte de données. |
| Héritage | Mot-clé extends ou flèche | Table unique avec des NULLs OU plusieurs tables | Dispersion dans une seule table ou jointures complexes dans plusieurs. |
📝 Meilleures pratiques pour l’alignement
Pour minimiser les frictions futures, les équipes doivent adopter des stratégies qui privilégient l’alignement entre les modèles logiques et physiques. Cela implique la communication et les processus, et non seulement la technologie.
- Approche schema-first : Définissez le schéma de base de données avant d’écrire le code de l’application. Cela garantit que le niveau de stockage impose les contraintes, et que le code doit s’y adapter.
- Approche code-first : Définissez les classes en premier, puis générez le schéma. Cela est plus rapide pour le développement, mais comporte le risque de créer une structure physique inefficace, difficile à optimiser ultérieurement.
- Documentation : Maintenez un document vivant qui associe les propriétés de classe aux colonnes de la base de données. Cela constitue une source unique de vérité pour les développeurs et les administrateurs de bases de données.
- Cycles de revue : Intégrez les revues du schéma de base de données au processus de revue de code. Aucun code ne doit être fusionné sans vérifier que les scripts de migration correspondent aux modifications des classes.
🛠️ Gestion des systèmes hérités
Tous les projets ne commencent pas sur une feuille blanche. De nombreuses organisations doivent faire face à des bases de données héritées qui ne correspondent pas aux diagrammes de classes actuels. Le refactoring dans ce contexte exige une prudence particulière.
- Modèle de figue étrangleur : Déplacez progressivement les nouvelles fonctionnalités vers un nouveau schéma tout en maintenant le système ancien opérationnel. Cela permet au diagramme de classes d’évoluer sans rompre les intégrations existantes.
- Vues et préparation : Créez des vues de base de données pour présenter les données dans un format correspondant au nouveau diagramme de classes sans modifier immédiatement les tables sous-jacentes.
- Migration incrémentale : Déplacez les données par lots. Vérifiez l’intégrité après chaque lot avant de passer au suivant. Cela minimise le risque de corruption des données pendant la transition.
🚀 Vers l’avenir
L’écart entre le diagramme de classes et le schéma de base de données est un défi inhérent du génie logiciel. Il découle des différences fondamentales entre la manière dont les ordinateurs traitent la logique et celle dont ils stockent les informations. Il n’existe pas de solution parfaite qui élimine entièrement cette friction, mais il existe des stratégies pour la gérer efficacement.
En comprenant les subtilités de l’héritage, des relations, des types de données et des conventions de nommage, les équipes peuvent réduire la fréquence des erreurs. Les audits réguliers et l’utilisation d’outils automatisés aident à maintenir la synchronisation au fil du temps. L’objectif n’est pas de faire ressembler la base de données exactement au code, mais de garantir que la correspondance entre les deux est transparente, cohérente et performante. Lorsque le stockage physique s’aligne sur la conception logique, le développement devient plus prévisible, et le système reste stable sous charge.