











Na arquitetura de software moderna, a desconexão entre o modelo orientado a objetos usado no código da aplicação e o modelo relacional usado no armazenamento persistente é um desafio constante. Os desenvolvedores frequentemente enfrentam situações em que a representação visual das estruturas de dados em um diagrama de classes diverge significativamente da disposição física de tabelas e colunas no esquema do banco de dados. Essa discrepância não é meramente estética; representa uma fricção arquitetônica fundamental que pode levar a problemas de integridade de dados, gargalos de desempenho e custos aumentados de manutenção. Compreender as causas raiz dessas discrepâncias é essencial para construir sistemas robustos e escaláveis.
Quando um diagrama de classes não está alinhado com o esquema de banco de dados subjacente, isso cria uma incompatibilidade de impedância. Esse termo descreve o conjunto de dificuldades inerentes ao uso de linguagens de programação orientadas a objetos para resolver problemas que existem em um ambiente de banco de dados relacional. Enquanto o mundo dos objetos opera com instâncias, métodos e herança, o mundo do banco de dados depende de conjuntos, linhas e chaves estrangeiras. Superar essa lacuna exige decisões de design deliberadas e validação rigorosa.
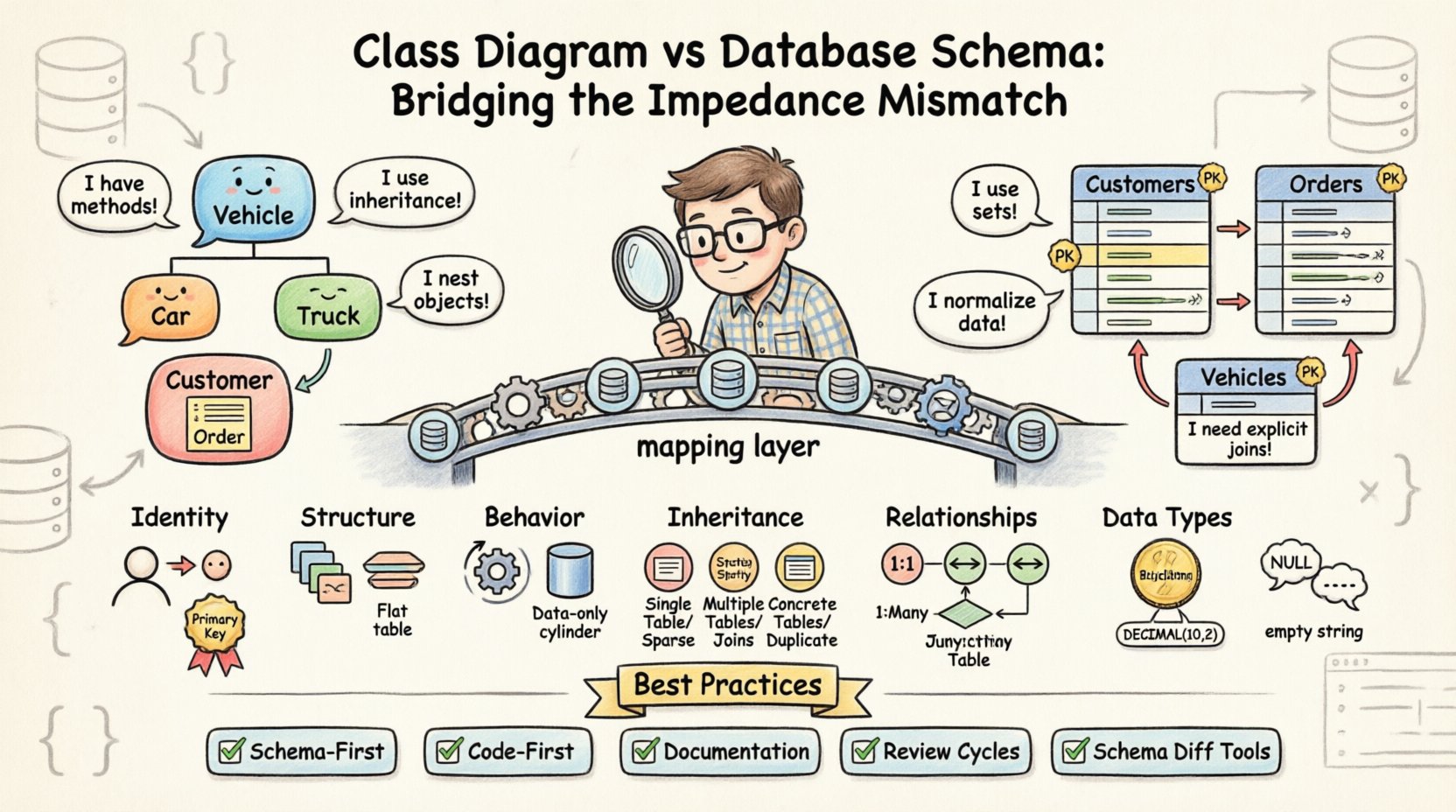
🔄 A Tensão Central: Objetos vs. Tabelas
A diferença fundamental reside na filosofia de armazenamento de dados. As classes orientadas a objetos encapsulam estado e comportamento juntos. Em contraste, os bancos de dados relacionais normalizam os dados para reduzir a redundância. Essa divergência cria várias áreas específicas onde os dois modelos têm dificuldade em se sincronizar.
- Identidade:Os objetos são identificados por referência de memória ou por um identificador único de objeto durante a execução. Os bancos de dados usam chaves primárias, frequentemente inteiros autoincrementáveis ou UUIDs, que existem independentemente do ciclo de vida da aplicação.
- Estrutura:Uma classe pode ter objetos aninhados complexos, coleções e referências circulares. Uma tabela de banco de dados não pode armazenar nativamente um objeto aninhado sem achatá-lo ou criar uma tabela separada.
- Comportamento:As classes contêm métodos que manipulam dados. As tabelas de banco de dados contêm apenas dados; qualquer lógica deve ser tratada por meio de procedimentos armazenados ou fora da camada do banco de dados.
Quando os desenvolvedores tentam mapear esses dois paradigmas diretamente sem uma abstração cuidadosa, erros ocorrem. A camada de mapeamento frequentemente atua como um tradutor, mas nenhum tradutor é perfeito. Nuances na lógica, tratamento de valores nulos e conversão de tipos são frequentemente perdidas na tradução.
🏗️ Discrepâncias Estruturais no Mapeamento
Uma das fontes mais comuns de discrepância envolve como as relações entre entidades são tratadas. Em um diagrama de classes, as relações são frequentemente representadas por linhas simples que indicam associações. Em um esquema de banco de dados, essas associações exigem restrições de chave estrangeira explícitas e frequentemente tabelas de junção intermediárias.
Hierarquias de Herança
Sistemas orientados a objetos prosperam com herança. Uma Veículo classe pode ter subclasses como Carro e Caminhão. Isso permite polimorfismo e reutilização de código. No entanto, bancos de dados relacionais não suportam herança nativamente. Para modelar isso, os engenheiros devem escolher entre estratégias específicas, cada uma com suas próprias compensações.
- Tabela por Hierarquia:Uma única tabela armazena todos os dados do pai e de todas as subclasses. Isso é simples, mas leva a colunas esparsas e valores nulos quando campos específicos de subclasses são usados.
- Tabela por Subclasse:Cada classe recebe sua própria tabela. A tabela pai armazena atributos comuns, enquanto as tabelas filhas armazenam os específicos, ligadas por uma chave estrangeira. Isso aumenta a complexidade das junções necessárias para recuperar um objeto completo.
- Tabela por Classe Concreta:Cada classe concreta recebe uma tabela completa contendo todos os atributos. Isso evita junções, mas exige a duplicação de dados comuns em várias tabelas.
Se o diagrama de classes mostra uma árvore de herança clara, mas o esquema do banco de dados usa uma única tabela plana, o esquema não corresponde ao modelo lógico. Isso pode levar a confusão durante a manutenção, pois os desenvolvedores podem esperar colunas específicas que não existem devido à estratégia de achatamento.
Associação e Agregação
Considere uma Cliente classe com uma coleção de Pedido objetos. No diagrama de classes, isso é uma relação um-para-muitos. No banco de dados, isso é representado por uma coluna de chave estrangeira na tabela Pedidos que faz referência à tabela Clientes tabela. No entanto, a direção da relação é frequentemente onde ocorrem discrepâncias.
- Relacionamentos muitos-para-muitos: Um diagrama de classes pode mostrar
AlunoeCursoligados por uma associação muitos-para-muitos. O banco de dados exige uma terceira tabela, frequentemente chamada de tabela de junção ou tabela ponte, para resolver isso. Se o esquema omitir essa tabela, a relação não poderá ser enforceada. - Cardinalidade: Um diagrama de classes pode indicar uma relação opcional (0..*). O esquema do banco de dados deve refletir isso com chaves estrangeiras nulas. Se o esquema exigir uma restrição NOT NULL, isso contradiz a definição da classe.
- Exclusão em Cascata: No código, excluir um objeto pai pode remover automaticamente os filhos. No banco de dados, isso exige regras de exclusão em cascata. Se essas regras não forem configuradas, registros órfãos permanecem, comprometendo a integridade dos dados.
🛡️ Integridade de Dados e Incompatibilidades de Tipo
Além da estrutura, os tipos de dados reais definidos na classe frequentemente não se alinham com os tipos de coluna do banco de dados. Embora os sistemas modernos ofereçam amplas capacidades de mapeamento, casos extremos frequentemente causam problemas.
Restrições de Nulidade
Em linguagens orientadas a objetos, um campo é frequentemente nulo por padrão, a menos que seja inicializado explicitamente. Em bancos de dados relacionais, a restrição NOT NULL é uma otimização de desempenho e integridade. Uma discrepância aqui leva a exceções em tempo de execução.
- Valores Padrão: Uma classe pode assumir que um campo de string tem como padrão uma string vazia. O banco de dados pode defini-lo como NULL. O código que espera uma string vazia falhará se receber NULL.
- Validação: A validação em nível de aplicação pode permitir que um campo seja nulo. O esquema do banco de dados rejeita isso. Isso cria um conflito entre a lógica de negócios e a camada de armazenamento.
Precisão e Escala Numéricas
Dados financeiros exigem alta precisão. Uma classe pode usar um BigDecimal ou Decimal tipo para lidar com moeda. O banco de dados deve suportar um tipo de coluna correspondente com precisão e escala definidas.
- Truncagem: Se a coluna do banco de dados for definida como
DECIMAL(10, 2)mas a lógica do aplicativo tenta armazenarDECIMAL(10, 4), ocorre perda de dados silenciosamente ou por meio de um erro. - Float vs. Decimal: Usar tipos de ponto flutuante para dinheiro é um anti-padrão comum. Embora uma classe possa usar
doublepara desempenho, o banco de dados deve forçar aritmética exata para evitar erros de arredondamento em contabilidade.
🏷️ Convenções de Nomenclatura e Identidade
A consistência na nomenclatura é vital para a manutenibilidade. No entanto, as convenções usadas em linguagens de programação frequentemente diferem das usadas em sistemas de gerenciamento de banco de dados.
Snake_case vs. CamelCase
Java e C# geralmente usam camelCase para propriedades de classe e nomes de campos. Muitos bancos de dados relacionais preferem snake_case para nomes de tabelas e colunas. Embora ferramentas de mapeamento frequentemente lidem com essa conversão automaticamente, a criação manual de esquemas pode violar essa regra.
- Sensibilidade a maiúsculas e minúsculas: Alguns bancos de dados são sensíveis a maiúsculas e minúsculas, enquanto outros não são. Uma coluna nomeada
FirstNameno banco de dados pode ser consultada comofirstnameno código, levando a erros dependendo da configuração do servidor. - Palavras Reservadas: Propriedades de classe podem usar nomes que são palavras-chave reservadas na linguagem do banco de dados, como
OrderouUser. Isso exige aspas ou alias, o que complica a geração de consultas.
Chaves Primárias e Chaves Estrangeiras
A escolha da estratégia de chave primária é outro ponto comum de atrito. As classes frequentemente dependem de chaves naturais (como um nome de usuário ou e-mail) ou chaves falsas (como um ID gerado automaticamente).
- Chaves Naturais:Usar um valor de negócios como chave primária pode tornar o esquema rígido. Se a regra de negócios mudar (por exemplo, um endereço de e-mail mudar), as referências de chave estrangeira precisarão ser atualizadas em todos os lugares.
- Chaves Falsas:Usar um ID auto-incrementado é mais seguro para junções, mas introduz uma coluna extra que não tem significado semântico na lógica de negócios.
⚡ Compromissos de Desempenho
Projetar um esquema que corresponda a um diagrama de classes frequentemente ignora implicações de desempenho. A correção teórica nem sempre equivale à eficiência operacional.
Normalização vs. Denormalização
Diagramas de classes frequentemente refletem estruturas de dados normalizadas para evitar redundâncias. No entanto, o desempenho do banco de dados às vezes se beneficia da denormalização para reduzir o número de junções necessárias durante operações de leitura.
- Complexidade de Junção:Uma hierarquia de classes complexa pode exigir múltiplas junções para buscar um único objeto. Em sistemas de alta carga, isso pode degradar significativamente os tempos de resposta.
- Cache:Dados denormalizados podem ser armazenados em cache mais facilmente. Se o esquema for muito normalizado, a camada de aplicação precisará executar lógica de reconstrução complexa, anulando os benefícios do cache.
Estratégias de Indexação
Índices são definidos ao nível do banco de dados para acelerar consultas, mas raramente são visíveis em um diagrama de classes. A ausência de definições de índice no design do esquema pode levar a consultas lentas.
- Índices de Chave Estrangeira:As colunas de chave estrangeira deveriam, idealmente, ser indexadas para acelerar as operações de junção. Se o esquema omitir esses índices, as pesquisas em dados relacionados escanearão todas as tabelas.
- Padrões de Busca:Se a aplicação pesquisar frequentemente por um atributo específico, um índice no banco de dados é necessário. Se o diagrama de classes destacar esse atributo, mas o esquema não o indexar, o desempenho sofrerá.
🔍 Detectando e Resolvendo Inconsistências
Identificar onde o esquema diverge do modelo é o primeiro passo rumo à resolução. Esse processo exige uma combinação de ferramentas automatizadas e auditoria manual.
Ferramentas de Diferença de Esquema
Ferramentas de comparação automatizadas podem destacar diferenças entre o estado esperado (derivado do diagrama de classes ou do código) e o estado real (o banco de dados físico).
- Detecção de Alterações:Essas ferramentas podem identificar colunas ausentes, tipos de dados alterados ou restrições removidas.
- Scripts de Migração:Eles podem gerar o SQL necessário para alinhar o esquema com o modelo, reduzindo erros manuais.
Auditoria Manual
A automação é útil, mas a revisão humana é necessária para lógicas complexas. Os revisores devem verificar o seguinte:
- Todos os campos da classe são representados por colunas no banco de dados?
- Os tipos de dados coincidem exatamente, incluindo comprimento e precisão?
- As relações estão corretamente restritas com chaves estrangeiras?
- As convenções de nomeação são consistentes em todos os aspectos?
Cenários Comuns de Mapeamento e Possíveis Problemas
| Cenário de Mapeamento | Representação do Diagrama de Classes | Representação do Esquema do Banco de Dados | Possível Problema |
|---|---|---|---|
| Um para Um | Linha única conectando duas classes | Chave estrangeira em uma tabela (restrição única) | A ausência da restrição única permite duplicatas. |
| Um para Muitos | Coleção de lista na classe pai | Chave estrangeira na tabela filha | A ausência de índice na chave estrangeira torna as consultas mais lentas. |
| Muitos para Muitos | Classe de ligação ou associação | Tabela de junção com duas chaves estrangeiras | A omissão da tabela de junção causa perda de dados. |
| Herança | Palavra-chave extends ou seta | Tabela única com NULLs OU múltiplas tabelas | Esparsidade em tabela única ou junções complexas em múltiplas. |
📝 Melhores Práticas para Alinhamento
Para minimizar o atrito futuro, as equipes deveriam adotar estratégias que priorizem o alinhamento entre os modelos lógico e físico. Isso envolve comunicação e processos, e não apenas tecnologia.
- Abordagem Baseada em Esquema: Defina o esquema do banco de dados antes de escrever o código da aplicação. Isso garante que a camada de armazenamento determine as restrições, e o código deve se adaptar a elas.
- Abordagem Baseada em Código: Defina as classes primeiro, depois gere o esquema. Isso é mais rápido para o desenvolvimento, mas corre o risco de criar uma estrutura física ineficiente que será difícil de otimizar posteriormente.
- Documentação:Mantenha um documento vivo que mapeie propriedades de classes para colunas do banco de dados. Isso serve como fonte única de verdade para desenvolvedores e administradores de banco de dados.
- Ciclos de Revisão:Inclua revisões do esquema do banco de dados no processo de revisão de código. Nenhum código deve ser mesclado sem verificar que os scripts de migração correspondem às alterações nas classes.
🛠️ Manipulação de Sistemas Legados
Nem todos os projetos começam com uma folha em branco. Muitas organizações precisam lidar com bancos de dados legados que não correspondem aos diagramas de classes atuais. Refatorar neste contexto exige cautela.
- Padrão Figueira Estranguladora:Mova gradualmente a nova funcionalidade para um novo esquema enquanto o sistema antigo permanece operacional. Isso permite que o diagrama de classes evolua sem quebrar integrações existentes.
- Visões e Estágio:Crie visualizações do banco de dados para apresentar os dados em um formato que corresponda ao novo diagrama de classes sem alterar imediatamente as tabelas subjacentes.
- Migração Incremental:Mova os dados em lotes. Verifique a integridade após cada lote antes de prosseguir para o próximo. Isso minimiza o risco de corrupção de dados durante a transição.
🚀 Avançando
A lacuna entre o diagrama de classes e o esquema do banco de dados é um desafio intrínseco na engenharia de software. Ela surge das diferenças fundamentais entre como os computadores processam lógica e como armazenam informações. Não existe uma solução perfeita que elimine completamente esse atrito, mas existem estratégias para gerenciá-lo de forma eficaz.
Ao compreender as nuances de herança, relacionamentos, tipos de dados e convenções de nomeação, as equipes podem reduzir a frequência de erros. Auditorias regulares e o uso de ferramentas automatizadas ajudam a manter a sincronização ao longo do tempo. O objetivo não é fazer o banco de dados se parecer exatamente com o código, mas garantir que o mapeamento entre eles seja transparente, consistente e eficiente. Quando o armazenamento físico alinha-se com o design lógico, o desenvolvimento torna-se mais previsível e o sistema permanece estável sob carga.