











W nowoczesnej architekturze oprogramowania rozłączenie między modelem obiektowym używanym w kodzie aplikacji a modelem relacyjnym używanym w trwałym przechowywaniu danych jest trwałą wyzwaniem. Deweloperzy często napotykają sytuacje, w których wizualne przedstawienie struktur danych na diagramie klas znacznie różni się od fizycznej struktury tabel i kolumn w schemacie bazy danych. Ta rozbieżność nie jest jedynie estetyczna; reprezentuje podstawowe napięcie architektoniczne, które może prowadzić do problemów z integralnością danych, zawieszeń wydajności i zwiększonego kosztu utrzymania. Zrozumienie przyczyn tych rozbieżności jest kluczowe do budowania solidnych, skalowalnych systemów.
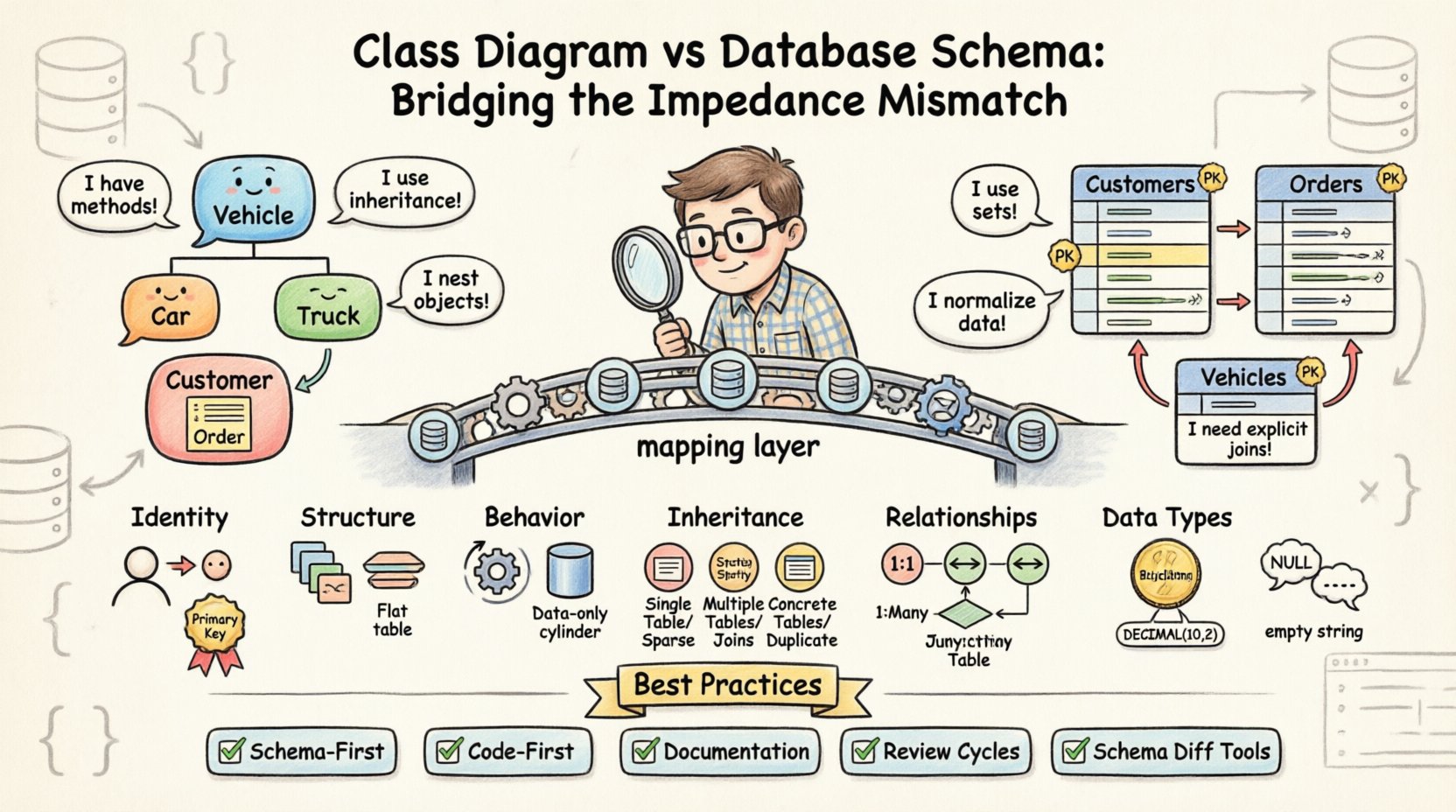
Gdy diagram klas nie jest zgodny z podstawowym schematem bazy danych, powstaje niezgodność impedancji. Ten termin opisuje zbiór trudności inherentnych w używaniu języków programowania zorientowanych obiektowo do rozwiązywania problemów występujących w środowisku bazy danych relacyjnych. Podczas gdy świat obiektów działa na instancjach, metodach i dziedziczeniu, świat bazy danych opiera się na zbiorach, wierszach i kluczach obcych. Przebranie tej przerwy wymaga celowych decyzji projektowych i rygorystycznej weryfikacji.
🔄 Podstawowe napięcie: obiekty vs. tabele
Podstawowa różnica leży w filozofii przechowywania danych. Klasy zorientowane obiektowo łączą stan i zachowanie w jednym. Przeciwnie, bazy danych relacyjnych normalizują dane w celu zmniejszenia nadmiarowości. Ta rozbieżność tworzy kilka konkretnych obszarów, w których oba modele mają trudności z synchronizacją.
- Tożsamość:Obiekty są identyfikowane przez odniesienie do pamięci lub unikalny identyfikator obiektu w czasie działania. Bazy danych używają kluczy głównych, często liczb całkowitych zwiększanych automatycznie lub UUID, które istnieją niezależnie od cyklu życia aplikacji.
- Struktura:Klasa może mieć złożone zagnieżdżone obiekty, kolekcje i cykliczne odniesienia. Tabela bazy danych nie może domyślnie przechowywać zagnieżdżonego obiektu bez jego spłaszczenia lub utworzenia osobnej tabeli.
- Zachowanie:Klasy zawierają metody manipulujące danymi. Tabele bazy danych zawierają jedynie dane; wszelka logika musi być obsługiwana za pomocą procedur składowanych lub poza warstwą bazy danych.
Gdy deweloperzy próbują bezpośrednio przekształcić te dwa paradygmaty bez starannego abstrahowania, pojawiają się błędy. Warstwa mapowania często działa jak tłumaczy, ale żaden tłumaczy nie jest doskonały. Subtelności logiki, obsługa wartości null i konwersja typów często giną w tłumaczeniu.
🏗️ Strukturalne rozbieżności w mapowaniu
Jednym z najczęściej występujących źródeł rozbieżności jest sposób obsługi relacji między jednostkami. Na diagramie klas relacje często przedstawia się jako proste linie wskazujące na powiązania. W schemacie bazy danych te powiązania wymagają jawnych ograniczeń kluczy obcych i często pośrednich tabel połączeniowych.
Hierarchie dziedziczenia
Systemy zorientowane obiektowo czerpią siłę z dziedziczenia. KlasaVehicle może mieć podklasy takie jakCar iTruck. Pozwala to na polimorfizm i ponowne wykorzystanie kodu. Jednak bazy danych relacyjnych nie wspierają dziedziczenia domyślnie. Aby to zamodelować, inżynierowie muszą wybrać jedną z określonych strategii, każda z nią wiążącymi kompromisami.
- Tabela na hierarchię:Jedna tabela przechowuje wszystkie dane dla rodzica i wszystkich podklas. Jest to proste, ale prowadzi do rzadkich kolumn i wartości null, gdy używane są pola specyficzne dla podklasy.
- Tabela na podklasę:Każda klasa otrzymuje własną tabelę. Tabela rodzica przechowuje wspólne atrybuty, podczas gdy tabele potomne przechowują specyficzne, połączone kluczem obcym. Zwiększa to złożoność połączeń wymaganych do pobrania pełnego obiektu.
- Tabela na konkretną klasę:Każda konkretna klasa otrzymuje pełną tabelę zawierającą wszystkie atrybuty. Unika to połączeń, ale wymaga duplikowania wspólnych danych w wielu tabelach.
Jeśli diagram klas pokazuje jasną hierarchię dziedziczenia, ale schemat bazy danych używa pojedynczej płaskiej tabeli, schemat nie odpowiada modelowi logicznemu. Może to prowadzić do zamieszania podczas utrzymania, ponieważ deweloperzy mogą oczekiwać istnienia konkretnych kolumn, które nie istnieją z powodu strategii spłaszczenia.
Związki i agregacje
Rozważ klasę Klient z kolekcją Zamówienie obiektów. Na diagramie klas jest to relacja jeden do wielu. W bazie danych jest reprezentowana przez kolumnę klucza obcego w tabeli Zamówienia odnoszącej się do tabeli Klienci tabeli. Jednak kierunek relacji często jest miejscem, gdzie występują niezgodności.
- Relacje wiele do wielu: Diagram klas może pokazywać
StudentiPrzedmiotpołączone relacją wiele do wielu. Baza danych wymaga trzeciej tabeli, często nazywanej tabelą połączeniową lub mostową, aby rozwiązać ten problem. Jeśli schemat pomija tę tabelę, relacja nie może być wymuszona. - Moc zbioru: Diagram klas może wskazywać relację opcjonalną (0..*). Schemat bazy danych musi to odzwierciedlać za pomocą kluczy obcych dopuszczających wartości null. Jeśli schemat wymusza ograniczenie NOT NULL, sprzeciwia się definicji klasy.
- Usuwanie kaskadowe: W kodzie usunięcie obiektu nadrzędnego może automatycznie usunąć dzieci. W bazie danych wymaga to reguł usuwania kaskadowego. Jeśli nie są skonfigurowane, pozostają zanieczyszczone rekordy, naruszając integralność danych.
🛡️ Integralność danych i niezgodności typów
Poza strukturą, rzeczywiste typy danych zdefiniowane w klasie często nie zgadzają się z typami kolumn bazy danych. Choć nowoczesne systemy oferują obszerną możliwość mapowania, przypadki graniczne często powodują problemy.
Ograniczenia nullowalności
W językach obiektowych pole domyślnie jest nullowalne, chyba że jawnie zainicjalizowane. W bazach danych relacyjnych ograniczenie NOT NULL jest optymalizacją wydajności i integralności. Niezgodność tutaj prowadzi do wyjątków czasu wykonania.
- Wartości domyślne: Klasa może założyć, że pole typu string domyślnie ma wartość pustego ciągu. Baza danych może domyślnie nadać mu wartość NULL. Kod oczekujący pustego ciągu zawieje, jeśli otrzyma NULL.
- Weryfikacja: Weryfikacja na poziomie aplikacji może dopuszczać, aby pole było null. Schemat bazy danych go odrzuca. Powoduje to konflikt między logiką biznesową a warstwą przechowywania danych.
Dokładność i skala liczbowe
Dane finansowe wymagają wysokiej dokładności. Klasa może używać BigDecimal lub Dziesiętny typ do obsługi waluty. Baza danych musi obsługiwać odpowiedni typ kolumny z określoną precyzją i skalą.
- Przycinanie: Jeśli kolumna bazy danych jest zdefiniowana jako
DECIMAL(10, 2)ale logika aplikacji próbuje zapisaćDECIMAL(10, 4), dojdzie do utraty danych bez ostrzeżenia lub poprzez błąd. - Float vs. Dziesiętny: Używanie typów zmiennoprzecinkowych do pieniędzy to powszechna niepożądana praktyka. Choć klasa może używać
doubledla wydajności, baza danych powinna wymuszać dokładne obliczenia, aby zapobiec błędom zaokrąglenia w księgowości.
🏷️ Zasady nazewnictwa i tożsamość
Spójność w nazewnictwie jest kluczowa dla utrzymywalności. Jednak zasady stosowane w językach programowania często różnią się od tych używanych w systemach zarządzania bazami danych.
Snake_case vs. CamelCase
Java i C# zwykle używają camelCase dla właściwości klas i nazw pól. Wiele relacyjnych baz danych preferuje snake_case dla nazw tabel i kolumn. Choć narzędzia mapowania często automatycznie obsługują tę konwersję, ręczne tworzenie schematu może naruszyć tę zasadę.
- Wrażliwość na wielkość liter: Niektóre bazy danych są wrażliwe na wielkość liter, inne nie. Kolumna o nazwie
FirstNamew bazie danych może być zapytana jakofirstnamew kodzie, co może prowadzić do błędów w zależności od konfiguracji serwera. - Słowa kluczowe: Właściwości klasy mogą używać nazw, które są słowami kluczowymi zarezerwowanymi w języku bazy danych, takich jak
OrderlubUser. Wymagają one użycia cudzysłowów lub aliasów, co komplikuje generowanie zapytań.
Klucze główne i klucze obce
Wybór strategii klucza głównego to kolejny powszechny punkt napięcia. Klasy często opierają się na kluczach naturalnych (takich jak nazwa użytkownika lub adres e-mail) lub kluczach zastępczych (takich jak generowany automatycznie identyfikator).
- Klucze naturalne:Używanie wartości biznesowej jako klucza głównego może sprawić, że schemat stanie się sztywny. Jeśli reguła biznesowa ulegnie zmianie (np. adres e-mail się zmieni), odniesienia kluczy obcych muszą zostać zaktualizowane wszędzie.
- Klucze zastępcze:Używanie identyfikatora zwiększającego się automatycznie jest bezpieczniejsze przy łączeniach, ale wprowadza dodatkową kolumnę, która nie ma znaczenia semantycznego w logice biznesowej.
⚡ Zdyscyplinowanie wydajności
Projektowanie schematu zgodnego z diagramem klas często pomija skutki wydajnościowe. Poprawność teoretyczna nie zawsze oznacza efektywność operacyjną.
Normalizacja wobec denormalizacji
Diagramy klas często odzwierciedlają struktury danych znormalizowane, aby uniknąć nadmiarowości. Jednak wydajność bazy danych czasem korzysta z denormalizacji, aby zmniejszyć liczbę łączeń wymaganych podczas operacji odczytu.
- Złożoność łączeń:Złożona hierarchia klas może wymagać wielu łączeń, aby pobrać pojedynczy obiekt. W systemach o wysokim ruchu może to znacząco pogorszyć czasy odpowiedzi.
- Buforowanie:Dane denormalizowane można łatwiej buforować. Jeśli schemat jest zbyt znormalizowany, warstwa aplikacji musi wykonywać skomplikowaną logikę odtwarzania, co anuluje korzyści z buforowania.
Strategie indeksowania
Indeksy są definiowane na poziomie bazy danych w celu przyspieszenia zapytań, ale rzadko są widoczne na diagramie klas. Brak definicji indeksów w projekcie schematu może prowadzić do wolnych zapytań.
- Indeksy kluczy obcych:Kolumny kluczy obcych powinny być indeksowane, aby przyspieszyć operacje łączenia. Jeśli schemat pomija te indeksy, wyszukiwanie danych powiązanych będzie wymagało skanowania całych tabel.
- Wzorce wyszukiwania: Jeśli aplikacja często wyszukuje według określonej atrybutu, wymagany jest indeks bazy danych. Jeśli diagram klas wyróżnia ten atrybut, ale schemat go nie indeksuje, wydajność będzie cierpiała.
🔍 Wykrywanie i rozwiązywanie niezgodności
Określenie, gdzie schemat odbiega od modelu, to pierwszy krok w kierunku rozwiązania. Ten proces wymaga połączenia narzędzi automatycznych i ręcznej audytyzacji.
Narzędzia do porównania schematów
Narzędzia automatycznego porównania mogą wyróżnić różnice między oczekiwanym stanem (wyprowadzonym z diagramu klas lub kodu) a rzeczywistym stanem (fizyczna baza danych).
- Wykrywanie zmian: Te narzędzia mogą wykryć brakujące kolumny, zmienione typy danych lub usunięte ograniczenia.
- Skrypty migracji: Mogą generować kod SQL potrzebny do dopasowania schematu do modelu, zmniejszając błędy ręczne.
Ręczna audytyzacja
Automatyzacja jest pomocna, ale przeglądu ludzkiego potrzeba przy skomplikowanej logice. Recenzenci powinni zweryfikować następujące punkty:
- Czy wszystkie pola klasy są reprezentowane przez kolumny bazy danych?
- Czy typy danych są dokładnie takie same, w tym długość i dokładność?
- Czy relacje są odpowiednio ograniczone za pomocą kluczy obcych?
- Czy zasady nazewnictwa są spójne we wszystkich przypadkach?
Typowe scenariusze mapowania i potencjalne problemy
| Scenariusz mapowania | Reprezentacja diagramu klas | Reprezentacja schematu bazy danych | Potencjalny problem |
|---|---|---|---|
| Jeden do jednego | Pojedyncza linia łącząca dwie klasy | Klucz obcy w jednej tabeli (ograniczenie unikalności) | Brak ograniczenia unikalności pozwala na powielanie danych. |
| Jeden do wielu | Zbiór list w klasie nadrzędnej | Klucz obcy w tabeli potomnej | Brak indeksu na kluczu obcym spowalnia zapytania. |
| Wiele do wielu | Klasa połączeniowa lub asocjacja | Tabela pośrednia z dwoma kluczami obcymi | Pominięcie tabeli pośredniej powoduje utratę danych. |
| Dziedziczenie | Słowo kluczowe extends lub strzałka | Jedna tabela z NULL-ami lub wiele tabel | Rzadkość danych w jednej tabeli lub złożone łączenia w wielu. |
📝 Najlepsze praktyki w zakresie dopasowania
Aby zmniejszyć przyszłe trudności, zespoły powinny stosować strategie, które dają priorytet dopasowaniu modeli logicznego i fizycznego. Dotyczy to komunikacji i procesów, a nie tylko technologii.
- Podejście oparte na schemacie: Zdefiniuj schemat bazy danych przed napisaniem kodu aplikacji. Zapewnia to, że warstwa przechowywania określa ograniczenia, a kod musi się do nich dostosować.
- Podejście oparte na kodzie: Najpierw zdefiniuj klasy, a następnie wygeneruj schemat. Jest to szybsze podczas rozwoju, ale może prowadzić do nieefektywnej struktury fizycznej, którą trudno będzie później zoptymalizować.
- Dokumentacja:Utrzymuj żywy dokument, który mapuje właściwości klas na kolumny bazy danych. Służy on jako jedyny źródło prawdy dla programistów i administratorów baz danych.
- Cykle przeglądu:Załącz przeglądy schematu bazy danych do procesu przeglądu kodu. Żaden kod nie powinien być scalony bez potwierdzenia, że skrypty migracji odpowiadają zmianom w klasach.
🛠️ Obsługa systemów dziedziczonych
Nie wszystkie projekty zaczynają się od czystej kartki. Wiele organizacji musi radzić sobie z systemami baz danych dziedzicznymi, które nie odpowiadają aktualnym diagramom klas. Refaktoryzacja w tym kontekście wymaga ostrożności.
- Wzorzec drzewa strangler fig:Stopniowo przenieś nowe funkcje do nowego schematu, podczas gdy stary system pozostaje aktywny. Pozwala to na ewolucję diagramu klas bez naruszania istniejących integracji.
- Widoki i etapowanie:Utwórz widoki bazy danych, aby przedstawić dane w formacie odpowiadającym nowemu diagramowi klas, nie zmieniając natychmiast podstawowych tabel.
- Migracja stopniowa:Przenieś dane partiami. Sprawdź integralność po każdej partii przed przejściem do następnej. Zmniejsza to ryzyko uszkodzenia danych podczas przejścia.
🚀 Postępowanie dalej
Rozłączenie między diagramem klas a schematem bazy danych to inherentne wyzwanie w inżynierii oprogramowania. Powstaje z podstawowych różnic między sposobem, w jaki komputery przetwarzają logikę, a sposobem, w jaki przechowują informacje. Nie ma doskonałego rozwiązania, które całkowicie eliminowałoby tę napięcie, ale istnieją strategie pozwalające na skuteczne zarządzanie nią.
Zrozumienie subtelności dziedziczenia, relacji, typów danych i zasad nazewnictwa pozwala zespołom zmniejszyć częstotliwość błędów. Regularne audyty i wykorzystanie narzędzi automatyzacji pomagają utrzymać synchronizację w czasie. Celem nie jest doprowadzenie bazy danych do dokładnego odzwierciedlenia kodu, ale zapewnienie przejrzystości, spójności i wydajności mapowania między nimi. Gdy fizyczne przechowywanie danych dopasowuje się do projektu logicznego, rozwój staje się bardziej przewidywalny, a system pozostaje stabilny pod obciążeniem.